![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Compaq Tru64 UNIX operating system fully supports the following Chinese codesets by including locales and codeset conversion support:
It also provides codeset conversion support for the following codesets:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The DEC Hanyu codeset, denoted by dechanyu, consists of the following character sets:
DEC Hanyu uses a combination of single-byte, two-byte, and four-byte data to represent ASCII characters, symbols, or ideographic characters.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
All ASCII characters can be represented in the form of single-byte 7-bit data in DEC Hanyu. That is, the most significant bit (MSB) of ASCII characters is always set off.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
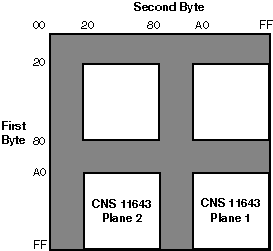
Each CNS 11643 character is represented by a two-byte code in DEC Hanyu, which complies with the CNS 11643 standard. The MSB of the first byte is always set on while that of the second byte can be on for the first character plane or off for the second character plane. See Figure 2-1.

The first byte of a CNS 11643 code determines the row number of the character, while the second byte determines its column number. Table 2-1 illustrates the code range of a CNS 11643 code.
Character Plane |
1st Byte (hex) |
2nd Byte (hex) |
|---|---|---|
Plane 1 |
A1 to FE |
A1 to FE |
Plane 2 |
A1 to FE |
21 to 7E |
The following formulas illustrate the code of a CNS 11643 character in relation to its row and column numbers.
CNS 11643 plane 1 character:
CNS 11643 Plane 2 character:
For example, if a character is positioned at the first column of the 36th row on CNS 11643 plane 1, its encoding value is calculated as follows:
Its encoded value is C4A1.
Similarly, if a character is positioned at the first column of the 36th row on CNS 11643 plane 2, its encoding value is calculated as follows:
Its encoded value is C421.
Figure 2-2 illustrates the division of a two-byte code space and the position of CNS 11643 characters.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
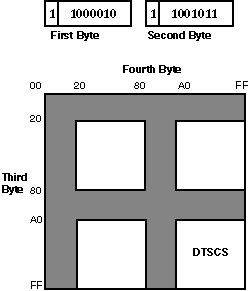
Each DTSCS character is represented by a four-byte code in DEC Hanyu. The first two bytes are the leading codes, namely 0xC2 0xCB, which are used as a designator sequence for the DTSCS character set. The MSB of the third and fourth bytes is set on for the EDPC Recommended Character Set.
![]()
Figure 2-4 illustrates the 4-byte code space and the position of DTSCS characters.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
In addition to the CNS11643 and the DTSCS character sets described above, DEC Hanyu provides 3,587 positions for user-defined characters (UDC). The positions for UDCs are those unused (but not reserved) code points on the CNS 11643 first and second character planes. Therefore, the encoding of UDC is exactly the same as that of CNS 11643 except that they occupy different regions, as shown in Table 2-2.
Character Plane |
Number of UDC |
Code Range |
|---|---|---|
Plane 1 |
145 |
FDCC - FEFE |
Plane 1 |
2,256 |
AAA1 - C1FE |
Plane 2 |
1,186 |
F245 - FE7E |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Taiwanese EUC (extended UNIX code), denoted as eucTW, is another codeset to support CNS 11643. The design of Taiwanese EUC allows the 16 character planes of CNS 11643 to be encoded in a unified way. A stream of data encoded in Taiwanese EUC can contain characters defined in ASCII and the 16 character planes. Figure 2-5 illustrates the encoding of Taiwanese EUC.
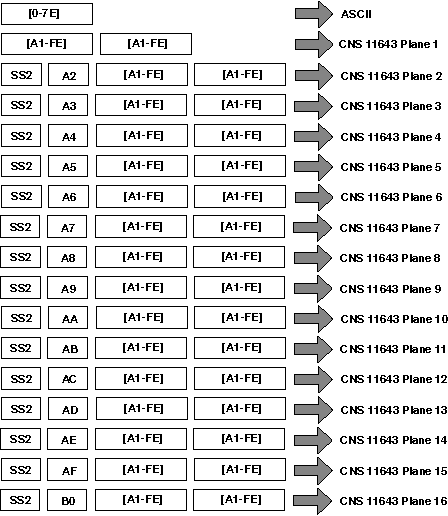
Taiwanese EUC uses the Single-Shift 2 control character (SS2) and an additional byte to specify a character plane. The only exception is the first plane, which does not require leading codes. Instead, two bytes specify a character's position on the first plane. The first byte determines its row number, while the second determines its column number. The MSBs of the two bytes are set on.
In this release, only the characters defined in the first and second planes of CNS 11643 and those in the EDPC Recommended Character Set that have been remapped into the third and fourth character planes of the revised CNS 11643-1992 are supported in Taiwanese EUC. Other characters that were added to the CNS 11643-1992 standard are not supported.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
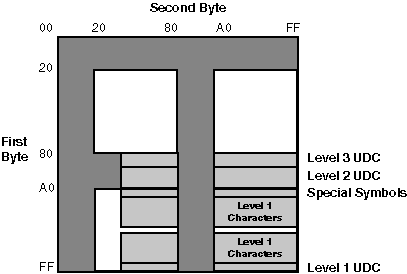
The Big-5 codeset, denoted as big5 is the only codeset that supports the Big-5 character set. The encoding of the Big-5 codeset is similar to that of CNS 11643 in DEC Hanyu. Each Big-5 character is represented by a two-byte code which complies with the Big-5 standard. The MSB of the first byte is always set on while that of the second byte can be set on or off.
The Big-5 code range is defined as shown in Table 2-3.
Character |
Number of Characters |
Code Range |
|---|---|---|
Special symbols |
408 |
A140-A3BF |
Level 1 characters |
5,401 |
A440-C67E |
Level 2 characters |
7,652 |
C940-F9D5 |
In addition to the code points for special symbols and Chinese characters shown in Table 2-3, three areas are set aside for user-defined spaces. Some vendors in Taiwan support user-defined characters in the code ranges shown in Table 2-4.
Character |
Number of Character |
Code Range |
|---|---|---|
Level 1 user-defined space |
785 |
FA40-FEFE |
Level 2 user-defined space |
2,983 |
8E40-A0FE |
Level 3 user-defined space |
2,041 |
8140-8DFE |
The valid ranges of the two bytes are:
Byte |
Valid Ranges |
|---|---|
First byte |
81-FE |
Second byte |
40-7E and A1-FE |
Figure 2-6 illustrates the encoding of the Big-5 codeset in a two-byte code space.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The ASCII, GB2312-80 and extended GB character sets are combined to form the DEC Hanzi codeset.
DEC Hanzi, denoted as dechanzi, uses a two-byte data representation for symbols and ideographic characters defined in the GB2312-80 character set. To differentiate GB2312-80 codes from ASCII codes, the MSB of the first byte is always set on while that of the second byte is on for GB2312-80 and off for extended GB, as shown in Figure 2-7.
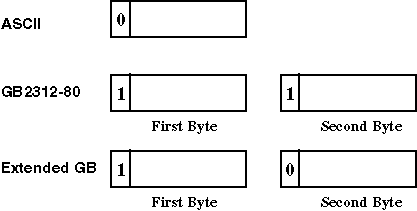
The first byte of a two-byte code determines its row number, while the second byte determines its column number.
The following formulas illustrate the code of a GB2312-80 character or an extended GB character in relation to its row and column numbers.
GB2312-80 character:
Extended GB character:
For example, if a character is positioned at the first column of the 16th row on the GB2312-80 code plane, its encoding value is calculated as follows:
Its encoded value is B0A1.
Similarly, if a character is positioned at the first column of the 16th row on the extended GB code plane, its encoding value is calculated as follows:
Its encoded value is B021.
Figure 2-8 illustrates the division of a two-byte code space and the position of the Chinese character sets.
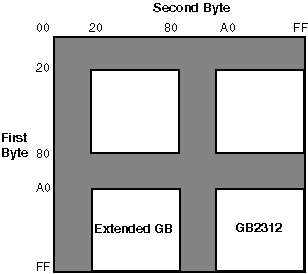
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Shift Big-5 codeset, denoted as sbig5, is a variant of the Big-5 codeset. The difference between the two is that the second byte of some Big-5 characters is mapped to other values to form Shift Big-5 characters. Table 2-5 illustrates the mappings of Big-5 characters to Shift Big-5 characters.
Big-5 (Second Byte) |
Shift Big-5 (Second Byte) |
|---|---|
40 |
30 |
5B |
31 |
5C |
32 |
5D |
33 |
5E |
34 |
5F |
35 |
60 |
36 |
7B |
37 |
7C |
38 |
7D |
39 |
7E |
9F |
The Shift Big-5 codeset can be used in codeset conversion and terminal display. Refer to Section 2.9 for details.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Telecode codeset (called Mitac Telex in early versions of the operating system), denoted as telecode, consists of 2 character planes. Each character plane has 8836 character positions. In plane 1, standard characters occupy positions 0001 to 8045; the remaining 791 positions are for user-defined characters. In plane 2, standard characters occupy positions 0001 to 8489; the remaining 346 positions are for user-defined characters. Telecode uses 2-byte values to represent characters on both planes.
Note
For information about the character sets encoded by Telecode, refer to Chinese Code For Data Communication.
Telecode can be used in codeset conversion and terminal display. Refer to Section 2.9 for further details.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
To differentiate plane 1 code from plane 2 code, the MSB is set on in both bytes of a plane 1 character code. You can use the following formula to calculate the value of a plane 1 character from its position on the plane:
First byte = M + 161
Second byte = N + 161 - M x 94
In this formula, N is the position of the character and M = N / 94.
For example, if a character is at position 2502 on plane 1, its encoded value is BBDB, which is calculated as follows:
N = 2502, M = 2502/94 = 26
First byte = 26 + 161 = 187 (or, BB (hex))
Second byte = 2502 + 161 - 26 x 94 = 219 (or, DB (hex))
![]()
![]()
![]()
![]()
![]()
![]()
![]()
To differentiate plane 2 code from plane 1 code, the MSB of the first byte is set on and the second byte is set off for each plane 2 character code. You can use the following formula to calculate the value of a plane 2 character from its position:
First byte = M + 161
Second byte = N + 33 - M x 94
In this formula, N is the position of the character on the plane and M = N / 94.
For example, if a character is at position 2502 on plane 2, its encoded value is BB5B, which is calculated as follows:
N = 2502, M = 2502/94 = 26
First byte = 26 + 161 = 187 (or, bb (hex))
Second byte = 2502 + 33 - 26 x 94 = 91 (or, 5B (hex))
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The UCS codeset is a standard character encoding for the universal character set (UCS) specified in Unicode and ISO/IEC 10646. There are two encoding schemes for UCS. An implementation that parses in 16-bit units (2 octets) is known as UCS-2. This is the canonical Unicode encoding in wide use on personal computers. An implementation that parses in 32-bit units (4 octets) is known as UCS-4. This is the canonical ISO/IEC 10646 encoding that is in use on systems that can support larger data unit size.
On Compaq Tru64 UNIX, UCS-2 and UCS-4 can be used in codeset conversion. In addiiton, UCS-4 is used as an internal procedsscode for some locales. For codeset conversion, see Section 2.9. For locale variants, see Chapter 3.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Unicode and ISO/IEC 10646 standards define transformation formats for the UCS. The following UCS transformation formats (UTFs) exist mainly to transform UCS values into sequences of bytes for handling by various byte-oriented protocols:
The current version of Compaq Tru64 UNIX supports UTF-8. UTF-8 can be used in codeset conversion and in the universal.UTF-8 locale. For codeset conversion, see Section 2.9. For locale variants, see Chapter 3.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Users may sometimes need to convert files from one codeset to another. The iconv utility provided by Compaq Tru64 UNIX is used to convert the encoding of characters in one codeset to another and write the results to standard output. Table 2-6 shows the pairs of Chinese codeset converters that are provided.
DEC Hanyu |
Taiwanese EUC |
Big-5 |
Shift Big-5 |
Telecode |
DEC Hanzi |
UCS-4 |
UCS-2 |
UTF-8 |
|
|---|---|---|---|---|---|---|---|---|---|
DEC Hanyu |
- |
Y |
Y |
N |
Y |
Y |
Y |
Y |
Y |
Taiwanese EUC |
Y |
- |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
BIG-5 |
Y |
Y |
- |
Y |
Y |
Y |
Y |
Y |
Y |
Shift Big-5 |
N |
Y |
Y |
- |
N |
N |
N |
N |
N |
Telecode |
Y |
Y |
Y |
N |
- |
N |
N |
N |
N |
DEC Hanzi |
Y |
Y |
Y |
N |
N |
- |
Y |
Y |
Y |
UCS-4 |
Y |
Y |
Y |
N |
N |
Y |
- |
Y |
Y |
UCS-2 |
Y |
Y |
Y |
N |
N |
Y |
Y |
- |
Y |
UTF-8 |
Y |
Y |
Y |
N |
N |
Y |
Y |
Y |
- |
For example, the following command converts a DEC Hanyu file to Big-5:
% iconv -f dechanyu -t big5 <file>
Table 2-7 shows the various string names you can use as the parameters of the iconv utility.
Codeset |
String |
|---|---|
DEC Hanyu |
dechanyu |
Taiwanese EUC |
eucTW |
Big-5 |
big5 |
Shift Big-5 |
sbig5 |
Telecode |
telecode |
DEC Hanzi |
dechanzi |
Universal Codeset (4-octet form) |
UCS-4 |
Universal Codeset (2-octet form) |
UCS-2 |
Universal Transfer Format |
UTF-8 |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
When converting from one codeset to another, characters in the source codeset that have no corresponding code point in the destination codeset will not be converted. By default, the characters that cannot be converted are skipped and have no representation in the converted output.
You can control this behavior by using the ICONV_DEFSTR environment variable to define a default string to replace those unconvertible characters. If you specify a numeric value for this environment variable, the corresponding character value will be used.
The ICONV_DEFSTR environment variable affects all Chinese iconv converters. You can also use the "ICONV_DEFSTR_<from_code>_<to_code>" environment variable to control specific codeset conversion. For example to convert a DEC Hanyu input file to DEC Hanzi with unconvertible characters converted to "?", you would enter the following commands:
%setenv ICONV_DEFSTR_dehanyu_dechanzi "?" %iconv -f dechanyu -t dechanzi hanzi_input > hanyu_output
For codeset converters that end in UCS-2, UCS-4, or UTF-8, you can use the "U+XXXX" notation to specify the default character for conversion failure fallback.
Note
During cut-and-paste operations, those traditional Chinese characters that cannot be converted to Simplified Chinese characters are shown as default characters in the applications.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
When converting from the DEC Hanzi codeset to other Chinese codesets, one Simplified Chinese character may be mapped to multiple traditional Chinese characters. By default, the iconv utility picks up only the most likely candidate from a list of possible choices. You can control the behavior of the iconv utility with the ICONV_ACTION environment variables.
The ICONV_ACTION environment variable determines how the iconv utility behaves when there are one-to-many mappings. The possible values are:
Note
During cut-and-paste operations, the batch mode is always used for those nonunique characters.
Note
The ICONV_ACTION environment variable applies to simplified Chinese to traditional Chinese conversion only and has no effect on UCS-4 and UTF-8 converters.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Some user-defined characters in the Big-5 codeset have pre-defined mappings to user-defined spaces in DEC Hanyu. These mappings are the same as those supported by Pathworks/Hanyu. Table 2-8 shows this mapping.
DEC Hanyu |
Big-5 |
Code Size |
|---|---|---|
F321 - FB41 |
FA40 - FEFE |
785 |
FB42 - FEFE |
8E40 - 905C |
343 |
AAA1 - C1FE |
905D - 9EB8 |
2256 |
These predefined user-defined character mappings are supported by both the iconv methods and the terminal driver.
Because some user-defined characters do not have predefined mappings, Compaq recommends that you use only those user-defined characters that have predefined mappings.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Compaq Tru64 UNIX software provides a mechanism for you to use to configure your system to run applications with peripherals, such as terminals and printers, that support different codesets. You can specify the codesets for the applications, terminals, and printers independently as shown in Table 2-9. The Compaq Tru64 UNIX software automatically does the necessary codeset conversion.
Application Code |
Terminal Code |
Printer Code |
|---|---|---|
DEC Hanyu |
DEC Hanyu |
DEC Hanyu |
Taiwanese EUC |
Taiwanese EUC |
Taiwanese EUC |
Big-5 |
Big-5 |
Big-5 |
DEC Hanzi |
DEC Hanzi |
DEC Hanzi |
| Shift Big-5 Telecode |
|
Note
Chinese DECterm software supports only DEC Hanyu, Big5, or DEC Hanzi as its terminal code. You must activate the stty drive and set tcode to dechanyu when running in a Taiwanese EUC locale. For example:
%stty adec tcode dechanyu
For details about setting up codesets for terminals and printers, see Writing Software for the International Market.
![]()
![]()
![]()
![]()
![]()
![]()
![]()