The Tru64 UNIX Object File/Symbol Table Format Specification is the official definition of the object file and symbol table formats used for Tru64 UNIX object files. It also describes the legal uses of the formats and their interpretation.
This document treats in detail the file formats for object files and archive files. These files are described as follows:
ar(1)) is the tool used to create and update archive files.Tools that create, use, or otherwise interact with object or archive files should conform to the formatting and usage conventions outlined in this specification.
This section defines terms that are used throughout this document.
ld. This utility is the primary producer of executable object files and shared libraries. The object file format described in this specification originated from the System V COFF (Common Object File Format). Implementation-dependent varieties of the COFF format are used on many UNIX systems. Tru64 UNIX has altered and extended the object file format to serve as the basis for program development on Alpha systems. This extended version of COFF is referred to in this document as eCOFF.
All systems based on the Alpha architecture and running Tru64 UNIX employ the eCOFF object file format.
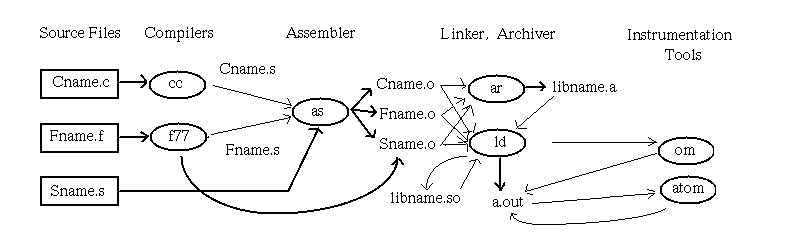
Many tools interact with objects and archives in the development environment. Object file producers create object files, and object file consumers read object files. A tool may be both a producer and a consumer. Figure 1-1 provides one view of the program development process from source files through executable object file production.
A summary of the functions of relevant system utilities and their relationship to objects and archives follows. Detailed information is available in reference pages.
Compilers are programs that translate source code into either intermediate code that can be processed by an assembler or an object file that can be processed by the linker (or executed directly). Accordingly, compilers may be direct or indirect producers of object files, depending on the compilation system. The compiler creates the initial symbol table.
Assemblers also produce object files. An assembler converts a compiler's output from assembly language (the intermediate form) into binary machine language. The result is traditionally a non-executable object file (.o file). The assembler lays out the sections of the object file and assigns data elements and code to the various sections. It also lays the groundwork for the relocation process performed by linkers.
A linker (or link-editor) accepts one or more object files as input and produces another object file, which may be an executable program. The linker performs relocation fixups and symbol resolution. It merges symbolic information and searches for referenced symbols in shared libraries and archive libraries. Linkers are producers and consumers of object files, and consumers of archive files.
The selection of command-line options determines what type of object the linker produces. A final link produces an executable object file or shared library. A partial link produces a relocatable object that can be included in a future link.
Loaders (sometimes referred to as dynamic linkers) load executable object files and shared libraries into system memory for execution. A loader may perform dynamic relocation and dynamic symbol resolution. It may also provide run-time support for loading and unloading shared objects and on-the-fly symbol resolution. The loader is a consumer of executable object files and shared libraries.
Debuggers are utilities designed to assist programmers in pinpointing errors in their programs. Debuggers are object file consumers, and they rely heavily on the debug symbol table information contained in object files.
Object instrumentation tools are both consumers and producers of object files. Their input is an executable object and, possibly, the shared libraries used by that executable object. Their output is the instrumented version of the executable program. Instrumentation involves modifying the application by adding calls to analysis procedures at basic block, procedure, or instruction boundaries. Depending on the tool, the aim may be to optimize the program or gather data to enable future optimizations.
The om object modification tool is an object transformation tool that performs post-link optimizations such as removal of unneeded instructions and data. om's input is a specially linked object file produced by the linker, and its output is a modified executable object file.
The cord tool is a post-link tool that rearranges procedures in an executable file to facilitate improved cache mapping.
These tools are object file consumers and producers.
UNIX profiling tools (such as Compaq's programmable profiling and program analysis tool, Atom) are object file producers and consumers. These tools examine an executable object and the shared libraries it uses and report information such as basic block counts and procedure calling hierarchies. They may also restructure the program to improve performance. Output includes files that store profiling data generated during execution of the instrumented application.
An archiver is a tool that produces and maintains archive files. It is a producer and a consumer of archive files and a consumer of object files.
Tools are available that read object files and dump (print) their contents in human-readable form. Examples are nm, odump, stdump, and dis. These tools are object file consumers.
The tools ostrip and strip reduce the size of an object file by removing certain portions of the file. The mcs tool modifies the comment section only. These tools are both consumers and producers of object files.
This document is organized to correspond to a conceptual breakdown of an object file's contents. The main components of an object file are described briefly in the remainder of this section.
A high-level view of the eCOFF object file contents is depicted in Figure 1-2.
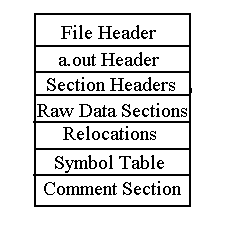
Header structures serve as a roadmap for navigating portions of the object file. They provide information about the size, location, and status of various sections and about the object as a whole. See Chapter 2 for more information.
Instructions and data are located in loadable segments of the object file. Instructions consist of all executable code. Data consists of uninitialized and initialized data, constants, and literals. Instructions and data are laid out in sections that are arranged into segments. The segments are then loaded to form part of the program's final image in memory. See Chapter 3 for more information.
The purpose of relocation is to defer writing the address-dependent contents of an object file until link time. Relocation entries are created by the compiler and assembler, and the necessary address adjustments are calculated by the linker. Information relevant to relocation is stored in section relocation entries and in the symbol table. In some instances, the loader subsequently performs dynamic relocation. See Chapter 4 and Chapter 6 for more details.
The symbol table contains information that describes the contents of an object file. Linkers rely on symbol table information to resolve references between object files. Debuggers use symbol table information to provide users with a source language view of a program's execution and its execution image. See Chapter 5 for more details.
Dynamic sections are utilized by the loader to create a process image for an executable object. These sections are present in shared object files only. Information is included to enable dynamic symbol resolution, dynamic relocation, and quickstarting of programs. See Chapter 6 for more details.
The comment section is a non-loadable section of the object file that is divided into subsections, each containing a different kind of information. This section is designed to be a flexible and expandable repository for supplemental object file data. See Chapter 7 for more information.
There are four principal types of object files:
Relocatable objects are object files that contain full relocation information. They are usually not executable. Pre-link producers- generally compilers and assemblers- always generate relocatable objects. The linker can also generate relocatable objects, but does not do so by default. See Chapter 4 for more details.
An object file is executable if it has no undefined symbol references. Executable objects can be static or dynamic.
Static executables are object files that are linked -non_shared. They use archive libraries only. They are fully resolved at link time and are loaded by the kernel's program execution facility.
Dynamic executables are object files that are linked -call_shared. They may use shared libraries, archive libraries or both. A dynamic executable is the compilation system's default output. The system loader performs dynamic linking, dynamic symbol resolution, and memory mapping for dynamic executables and the shared libraries they use.
Shared libraries are object files that provide collections of routines that can be used by dynamic executables. Although it contains executable code, a shared library by itself is not usually executable. Advantages of shared libraries include the ability to use updated libraries without relinking and a reduction in disk requirements. The reduction in disk requirements is achieved by providing a single copy of routines and data that might otherwise be duplicated in many executable object files.
Object file types can often be differentiated by their file name extension. Typically, relocatable objects have a .o file extension and shared libraries have a .so file extension. The default name for an executable object file is a.out. User-named executable files often do not have an extension.
It is important to be aware of which type of file is under discussion because the usage, content, and format of each kind of object file can vary significantly.
File compression is used widely on all kinds of files to save disk space. Similarly, object files can be compressed to save space. However, not all objects are candidates for compression and not all tools that handle objects also support compressed object files.
Decompressed data can be, at most, eight times the size of the compressed data. This rate of compression is the best case possible. At worst case, a compressed object will actually be larger than the decompressed version. Typically, however, a reduction of 50% to 75% in size is achieved.
When an object is compressed, the file header in uncompressed form precedes the compressed object file. The uncompressed file header's magic number indicates whether the remainder of the file contains a compressed object.
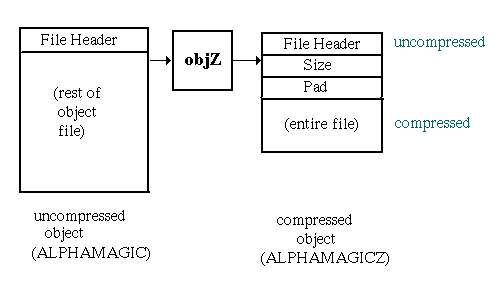
The value of "size" is the size of the uncompressed object in bytes. The archiver uses the "pad" value to indicate the bytes of padding it inserted. Both fields are 8-byte unsigned integers.
The most commonly compressed objects are archive members. Both the archiver and the linker support compressed objects used as archive members.
Executable objects and shared libraries cannot be compressed because the dynamic loader does not support compressed objects. To decompress an image, the loader would need to allocate space where it could write the decompressed image. Serious system penalties would be incurred because no part of the image would be shareable. However, a compressed object file can subsequently be decompressed and then loaded; this might be a way to temporarily save disk space in some circumstances.
The tool objZ is a Tru64 UNIX compression utility designed for object files. See the objZ(1) man page for details.
Archiving is a method used to enable manipulation of a large number of files as a single group, which may ease the task of file management. Any file can be archived. However, the archive files of primary interest in program development are archived object files that are used as libraries for static executables.
Object archives provide a means of working with a collection of objects simultaneously. System libraries such as "libc.a" and "libm.a" are object archives. Each library collects a set of related objects which provide a service in the form of callable APIs. Benefits of using archives in this fashion include the grouping of related functions and shorter build commands.
Another benefit of archive libraries is selective linking, whereby the linker extracts only needed objects from a library, instead of mapping the entire library with the image. For example, suppose the library libEx.a contained the objects x.o, y.o, and z.o. If the executable a.out depended on x.o to define a referenced symbol, but not on the other objects in the archive, only x.o would become part of the final executable object.
Another typical use for object archives is to subdivide large builds into subsystems, each of which is implemented as an archive that is eventually included in the final link.
Most tools that read objects will also read object archives. The linker applies special semantics in its handling of object archives, while other utilities treat an object archive as simply a list of object files.
Object archive members can also be compressed. In this case, each object that is an archive member is compressed as shown in Section 1.4.3. The archive file's administrative information is not compressed. Also, an archive file may contain both compressed and uncompressed file members.
More information on archives can be found in Chapter 8.
The object file and symbol table formats are versioned. This versioning scheme is independent of the operating system or hardware versions. It is not designed to be visible to end-users.
The object file and symbol table versions are each stored as a two-byte version stamp, with major and minor components of one byte each. The object file version is stored in the a.out header's vstamp field, and the symbol table version is stored in the symbolic header's vstamp field. The minor version is incremented when new features or compatible structure changes are introduced. The major version is incremented when an incompatible or semantically very significant change is made.
The object file version stamp covers the following structures:
filehdr.h)
a.out header (aouthdr.h)
scnhdr.h)
reloc.h)
scncomment.h)
coff_dyn.h)The symbol table version covers all symbol table structures and values defined in the header files sym.h and symconst.h.
The object file and symbol table versions can differ.
This document covers V3.13 of the object file and V3.13 of the symbol table.
Tool-specific version information for object file consumers may also be stored in the on-disk object file. If present, this information is stored in the comment section. See Chapter 7 for details.
A consistent set of basic abstract data types are used to build object file, symbol table, and dynamic loading structures. These names are defined in the header file coff_type.h.
The use of abstract types for all elements of these structures facilitates cross-platform builds. To build a tool to run on another platform, redefine the COFF basic abstract types for the new platform. This is done by inserting the new definitions and "#define ALTERNATE_COFF_BASIC_TYPES" prior to any object file or symbol table header files.
|
Name |
Size |
Alignment |
Purpose |
|
|
8 |
8 |
Unsigned program address |
|
|
8 |
8 |
Unsigned file offset |
|
|
8 |
8 |
Unsigned long word |
|
|
8 |
8 |
Signed long word |
|
|
4 |
4 |
Unsigned word |
|
|
4 |
4 |
Signed word |
|
|
2 |
2 |
Unsigned half word |
|
|
2 |
2 |
Signed half word |
|
|
1 |
1 |
Unsigned byte |
|
|
1 |
1 |
Signed byte |
Another data representation that is currently used exclusively in the optimization symbol table is LEB (Little Endian Byte) 128 format. This is a variable-length format for numeric data. The low-order seven bits of each LEB byte are interpreted as an integer value. The high bit, if set, indicates a continuation to the next byte. An LEB byte is illustrated in Figure 1-4. This format takes advantage of the likelihood that most numbers will be small. To form a large number, concatenate the 7-bit segments of the LEB128 bytes, as shown in Figure 1-5.
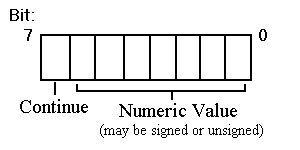
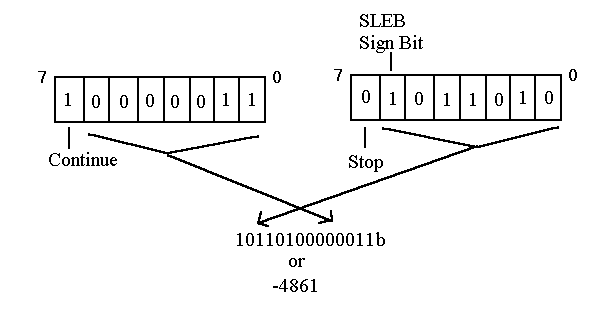
A value represented in LEB 128 format may be signed (SLEB) or unsigned (LEB). The second-highest bit in the final byte of an SLEB value is the sign bit. This means that the signed value has to be propagated only within one byte.
Object files originate from source files that may be coded in any of several high-level languages. The Tru64 UNIX eCOFF object file format supports the programming languages C, C++, Fortran, Bliss, Fortran90, Pascal, Cobol, Ada, PL1, and assembly. The choice of source language primarily impacts the symbol table, which includes the type and scope information used by the debugger. See Section 5.3.2 for more information.
The UNIX system is closely tied to the C programming language, and many tools that work with objects do not fully support non-C languages. Reference the specific tool's documentation for details.
Certain characteristics of the object file format are dependent on the Tru64 UNIX operating system. This section highlights those features and provides references to more detailed information.
The address space and image layout information covered in Chapter 2 are dependent on the operating system's virtual memory organization.
The kernel's virtual memory manager ensures that multiple processes can share all text and data pages. As soon as a process writes to one of those pages, it receives its own copy of that page. Because text pages are always mapped read-only, they are always shared for the lifetime of the process.
The virtual memory manager uses additional shareable pages, known as Page Table pages, to record the memory layout of a process. The linker's default address selection and the system library addresses are designed to maximize sharing of page table pages, which are implemented as "wired" memory, a limited system resource.
As part of this implementation, the text and data segments of shared libraries are usually separated in the address space. This separation allows many shared library text segments to be mapped in one area of memory. The Page Table pages used to describe an area of memory containing only text segments are shared by all processes that map one or more of those text segments into their address space. This sharing can result in significant savings in wired memory used by the system.
The GP-relative addressing technique is unique to Tru64 UNIX. See Section 3.3.2.
The operation of the system dynamic loader as described in Chapter 6 is system-dependent. Other loaders may behave differently.
The discussion of system shared library implementation using weak symbols is unique to Tru64 UNIX. See Section 6.3.4.1.
The 64-bit Alpha architecture defaults to using the little-endian byte-ordering scheme. In little-endian systems, the address of a multibyte data element is the address of its least significant byte, and the sign bit is located in the most significant bit. Bytes are numbered beginning at byte 0 for the lowest address byte, as shown in Figure 1-6
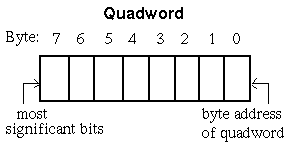
A big-endian byte-order can be infered by assuming all structure fields would be byte-swapped in a big-endian object. For example, big-endian byte order can be infered from Figure 1-6 by reversing the byte-numbering and moving the "byte address of quadword" label to the new location of byte 0. Non-obvious differences in the big-endian representation will be called out in the appropriate sections.
As discussed in Section 2.3.5, hardware constraints dictate text and data alignment. Unaligned references can cause fatal errors or negatively impact performance. For instance, on Alpha systems, dereferencing a pointer to a longword- or quadword-aligned object is more efficient than dereferencing a pointer to a byte- or word-aligned object. Special instructions exist for unaligned data memory accesses. The default assumption is that data is aligned.
TASO, the Truncated Address Space Option, is a migration path for applications with 32-bit assumptions onto 64-bit Alpha platforms. This topic is discussed in Section 2.3.3.2.
Relocation entries are heavily dependent on the Alpha instruction format. See Chapter 4 for details.
See the Assembly Language Programmer's Guide and Alpha Architecture Handbook for additional information about the Alpha Architecture.
Object and archive file structure declarations and value definitions are contained in the following header files in the /usr/include directory:
aouthdr.h ar.h coff_type.h coff_dyn.h cmplrs/cmrlc.h cmplrs/stsupport.h filehdr.h linenum.h pdsc.h reloc.h scnhdr.h sym.h symconst.h scncomment.h stamp.h
To access object file structures, it is preferable to use defined APIs. APIs provide a constant interface to an underlying structure which will evolve over time. See the libst_intro(3) manpage for reference.