One of the chief tasks of the compilation process is the production of a symbol table, which is a collection of data structures whose purpose is to store type, scope, and address information about program data. Compilers and assemblers create the symbol table. It is read and may be modified by linkers, profiling tools, and assorted object manipulation tools. It also contains information required for debugging.
For large applications, a single compilation can involve many program components, including source files, header files, and libraries. Data from all of these files must be described in the symbol table.
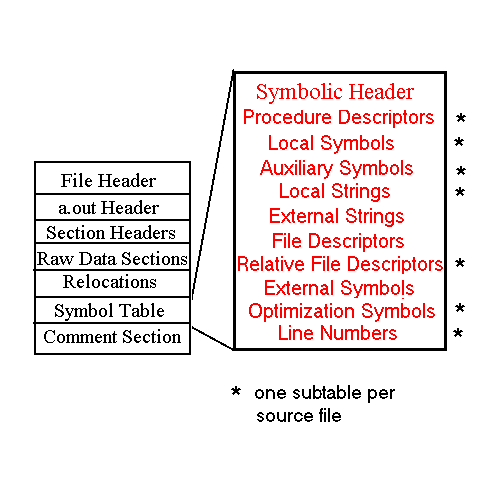
The Tru64 UNIX eCOFF symbol table, when present, comprises a large portion of the physical object file and is often considered a stand-alone entity. It is divided into numerous sections, including a header section that is used for navigation. The contents of the symbol table are shown in Figure 5-1.
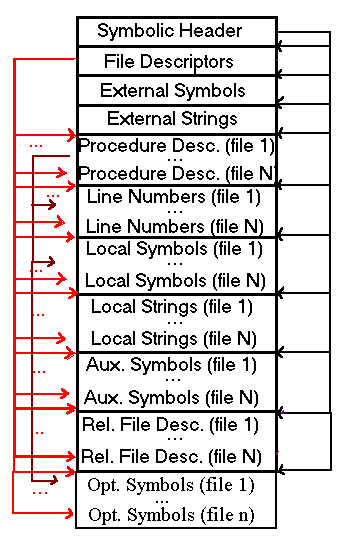
The symbol table has a hierarchical design. The sections storing local symbols, local strings, relative file descriptors, procedure descriptors, line numbers, auxiliary symbols, and optimization symbols are divided into subtables and organized by file. Local symbols, local strings, and optimization symbols are further broken down by procedure. Figure 5-2 depicts this hierarchy.
A particular symbol table may not contain all sections, for one of the following reasons:
The function of each symbol table section is summarized below:
Several tools are available to view the contents of the symbol table. See the stdump(1), odump(1), and nm(1) man pages.
This chapter covers symbol table organization and usage, concentrating on debugging issues in particular. The version of the symbol table covered is V3.13. The dynamic symbol table built by the linker is discussed separately in Section 6.3.3.
Version 3.13 of the symbol table includes the following new or changed features:
addressNil (see Section 5.3.1.2)
Unless otherwise specified, all structures described in this section are declared in the header file sym.h, and all constants are defined in the header file symconst.h.
typedef struct {
coff_ushort magic;
coff_ushort vstamp;
coff_int ilineMax;
coff_int idnMax;
coff_int ipdMax;
coff_int isymMax;
coff_int ioptMax;
coff_int iauxMax;
coff_int issMax;
coff_int issExtMax;
coff_int ifdMax;
coff_int crfd;
coff_int iextMax;
coff_long cbLine;
coff_off cbLineOffset;
coff_off cbDnOffset;
coff_off cbPdOffset;
coff_off cbSymOffset;
coff_off cbOptOffset;
coff_off cbAuxOffset;
coff_off cbSsOffset;
coff_off cbSsExtOffset;
coff_off cbFdOffset;
coff_off cbRfdOffset;
coff_off cbExtOffset;
} HDRR, *pHDRR;
SIZE - 144 bytes, ALIGNMENT - 8 bytes
Symbolic Header Fields
magic magicSym, defined as 0x1992.vstamp stamp.h header file:
|
|
|
|
|
|
ilineMax idnMax ipdMax isymMax ioptMax iauxMax issMax issExtMax ifdMax crfd iextMax cbLine cbLineOffset cbDnOffset cbPdOffset cbSymOffset cbOptOffset cbAuxOffset cbSsOffset cbSsExtOffset cbFdOffset cbRfdOffset cbExtOffset
General Notes
The size and offset fields describing symbol table sections must be set to zero if the section described is not present.
The cb*Offset fields are byte offsets from the beginning of the object file.
The i*Max fields contain the number of entries for a symbol table section. Legal index values for a symbol table section will range from 0 to the value of the associated i*Max field minus one.
For an explanation of packed and expanded line number entries, see the discussion in Section 5.3.2.2.
typedef struct fdr {
coff_addr adr;
coff_long cbLineOffset;
coff_long cbLine;
coff_long cbSs;
coff_int rss;
coff_int issBase;
coff_int isymBase;
coff_int csym;
coff_int ilineBase;
coff_int cline;
coff_int ioptBase;
coff_int copt;
coff_int ipdFirst;
coff_int cpd;
coff_int iauxBase;
coff_int caux;
coff_int rfdBase;
coff_int crfd;
coff_uint lang : 5;
coff_uint fMerge : 1;
coff_uint fReadin : 1;
coff_uint fBigendian : 1;
coff_uint glevel : 2;
coff_uint fTrim : 1;
coff_uint reserved: 5;
coff_ushort vstamp;
coff_uint reserved2;
} FDR, *pFDR;
SIZE - 96 bytes, ALIGNMENT - 8 bytes
See Section 5.3.2.1 for related information.
File Descriptor Table Entry Fields
adr PDR.adr field of the first procedure descriptor for this file. If no instructions are associated with this source file, this field should be set to 0. File descriptors that have been merged by source language in locally-stripped objects will have this field set to addressNil (-1).cbLineOffset cbLine cbSs rss issNil (-1) to indicate the source file name is unknown.issBase isymBase csym ilineBase cline ioptBase copt ipdFirst cpd iauxBase caux rfdBase crfd lang fMerge fReadin fBigendian glevel (-g compiler switch value) to the symbol table value is:
|
|
|
|
|
|
|
|
|
|
fTrimvstampHDRR.vstamp) value from the original object module (.o file) that is recorded by the linker. The linker may combine objects that were compiled at different times and potentially contain different versions of the symbol table. In post-link objects, this value may or may not match the version stamp in the symbolic header. For pre-link objects, the values in this field and the symbolic header stamp should be the same.reserved, reserved2
General Notes
The i*Base fields provide the starting indices of this file's subtables within the symbol table sections. If the associated count fields are set to 0, the base fields will also be set to zero.
For an explanation of packed and expanded line number entries, see the discussion in Section 5.3.2.2.
|
Name |
Value |
Comment |
|
|
0 |
|
|
|
1 |
|
|
|
2 |
|
|
|
3 |
|
|
|
4 |
|
|
|
5 |
|
|
|
6 |
|
|
|
7 |
|
|
|
8 |
|
|
|
9 |
|
|
|
10 |
Unused. |
|
|
11 |
|
|
|
12 |
|
|
|
13 |
Not used by all compilers - l |
|
|
14 |
|
|
|
31 |
Number of language codes available |
struct pdr {
coff_addr adr;
coff_long cbLineOffset;
coff_int isym;
coff_int iline;
coff_uint regmask;
coff_int regoffset;
coff_int iopt;
coff_uint fregmask;
coff_int fregoffset;
coff_int frameoffset;
coff_int lnLow;
coff_int lnHigh;
coff_uint gp_prologue : 8;
coff_uint gp_used : 1;
coff_uint reg_frame : 1;
coff_uint prof : 1;
coff_uint reserved : 13;
coff_uint localoff : 8;
coff_ushort framereg;
coff_ushort pcreg;
} PDR, *pPDR;
SIZE - 64 bytes, ALIGNMENT - 8 bytes
See Section 5.3.4 for related information.
Procedure Descriptor Table Entry Fields
adr addressNil (-1) for procedures with no text. This field may not be updated by the linker in symbol table versions prior to V3.13. To determine the procedure start address in pre-V3.13 symbol tables, use the algorithm described in Section 5.3.4.2.cbLineOffset FDR.cbLineOffset). isym stProc). The name of the procedure can be obtained from the iss field of the symbol table entry. isymNil (-1). This situation occurs for a static procedure in an object stripped of local symbol information.iline ilineNil (-1) to indicate that this procedure does not have line numbers.regmask regoffset iopt ioptNil (-1) to indicate that this procedure does not have optimization symbol entries.fregmask fregoffset frameoffset lnLow lnHigh -1 for alternate entry points, which is how an alternate entry point is identified. gp_prologue gp_used reg_frame prof�pg for gprof profiling.reserved localoff framereg pcreg
General Notes:
For more information on call frames, see Section 5.3.4.1.
If the value of gp_prologue is zero and gp_used is 1, a gp prologue is present but was scheduled into the procedure prologue.
For an explanation of packed and expanded line number entries, see the discussion in Section 5.3.2.2.
A procedure may be heavy-, light-, or null-weight. The weight of a procedure can be determined from its descriptor by using the following guidelines:
|
Weight |
Indications |
|
Heavy |
|
|
Light |
|
|
Null |
|
See the Calling Standard for Alpha Systems for details on the calling conventions for different weight procedures. Note that a calling routine does not need to know the weight of the routine being called.
Line numbers are represented using two formats: packed and expanded. The packed format is a byte stream that can be interpreted as described in Section 5.3.2.2 to build an expanded table that maps instructions to source line numbers. The LINER field is used to refer to a single entry in the expanded table. It is declared as:
typedef int LINER, *pLINER;
A second, newer form of line number information is located in the optimization symbols section. See Section 5.2.10 and Section 5.3.2.2.
typedef struct {
coff_long value;
coff_int iss;
coff_uint st : 6;
coff_uint sc : 5;
coff_uint reserved : 1;
coff_uint index : 20;
} SYMR, *pSYMR;
SIZE - 16 bytes, ALIGNMENT - 8 bytes
See Section 5.2.11, Section 5.3.4, and Section 5.3.8 for related information.
Local Symbol Table Entry Fields
value iss issBase field of a file descriptor table entry to the name of the symbol. If the symbol does not have a name, this field is set to issNil (-1). Generally, all user-defined symbols have names. A symbol without a name is one that has been created by the compilation system for its own use.st sc reserved index isymBase field in the file descriptor entry for an entry in the local symbol table or an offset from the iauxBase field for an entry in the auxiliary symbol table. indexNil, which is defined as (long)0xfffff. This value is used to indicate that the index is not a valid reference. The next two tables contain all defined values for the st and sc constants, along with short descriptions. However, these fields must be considered as pairs that have a limited number of possible pairings as explained in Section 5.2.11.
|
Constant |
Value |
Description |
|
|
0 |
Dummy entry |
|
|
1 |
Global variable |
|
|
2 |
Static variable |
|
|
3 |
Procedure argument |
|
|
4 |
Local variable |
|
|
5 |
Label |
|
|
6 |
Global procedure |
|
|
7 |
Start of block |
|
|
8 |
End of block, file, or procedure |
|
|
9 |
Member of class, structure, union, or enumeration |
|
|
10 |
User-defined type definition |
|
|
11 |
Source file name |
|
|
14 |
Static procedure |
|
|
15 |
Constant data |
|
|
17 |
Base class (for example, C++) |
|
|
18 |
Virtual base class (for example, C++) |
|
|
19 |
Data structure tag value (for example, C++ class or struct) |
|
|
20 |
Interlude (for example, C++) |
|
|
22 |
Fortran90 module definition; |
|
|
22 |
Namespace definition (for example, C++) |
|
|
23 |
Modifiers for current view of given module; |
|
|
23 |
Namespace use (for example, C++ "using"). |
|
|
24 |
Defines an alias for another symbols. Currently, only used for namespace aliases. |
sc) Constants|
Constant |
Value |
Description |
|
|
0 |
Dummy entry |
|
|
1 |
Symbol allocated in the |
|
|
2 |
Symbol allocated in the |
|
|
3 |
Symbol allocated in the |
|
|
4 |
Symbol allocated in a register |
|
|
5 |
Symbol value is absolute |
|
|
6 |
Symbol referenced but not defined in the current module |
|
|
7 |
Storage not allocated for this symbol |
|
|
9 |
Undefined TLS symbol |
|
|
11 |
Symbol contains debugger information |
|
|
13 |
Symbol allocated in the |
|
|
14 |
Symbol allocated in the |
|
|
15 |
Symbol allocated in the |
|
|
16 |
Parameter passed by reference (for example, Fortran or Pascal) |
|
|
17 |
Common symbol |
|
|
18 |
Small common symbol |
|
|
19 |
Parameter passed by reference in a register |
|
|
20 |
Variant record (for example, Pascal or Ada) |
|
|
20 |
File descriptor (for example, COBOL) |
|
|
21 |
Small undefined symbol |
|
|
22 |
Symbol allocated in the |
|
|
23 |
Report descriptor (for example, COBOL) |
|
|
24 |
Symbol allocated in the |
|
|
25 |
Symbol allocated in the |
|
|
26 |
Symbol allocated in the |
|
|
27 |
Symbol allocated in the |
|
|
29 |
TLS unallocated data |
|
|
30 |
Symbol allocated in the |
|
|
31 |
Symbol allocated in the |
|
|
32 |
Maximum number of storage classes |
typedef struct {
SYMR asym;
coff_uint jmptbl:1;
coff_uint cobol_main:1;
coff_uint weakext:1;
coff_uint reserved:29;
coff_int ifd;
} EXTR, *pEXTR;
SIZE - 24 bytes, ALIGNMENT - 8 bytes
External Symbol Table Entry Fields
asym valueississNil (-1) if there is no name for this symbol.stscreservedindexjmptblcobol_mainweakext reserved ifd ifdNil (-1) for undefined symbols and for some compiler system symbols.The relative file descriptor table provides a post-link mapping of file descriptor indices. The purpose of this table is to minimize work for the linker, which does not update symbol table references to local symbols. This information is used to obtain the file offset used to bias local symbol indices. Because this table is also known as the File Indirect Table, two declarations are included in the sym.h header file, as shown here.
typedef int RFDT, *pRFDT; typedef int FIT, *pFIT;
SIZE - 4 bytes, ALIGNMENT - 4 bytes
See Section 5.3.2.1 for related information.
The auxiliary symbol table entry is a 32-bit union. It is either interpreted as a TIR or RNDXR structure or as an integer value. See Section 5.3.7.3 for detailed instructions on reading the auxiliary symbols.
typedef union {
TIR ti;
RNDXR rndx;
coff_int dnLow;
coff_int dnHigh;
coff_int isym;
coff_int iss;
coff_int width;
coff_int count;
} AUXU, *pAUXU;
SIZE - 4 bytes, ALIGNMENT - 4 bytes
See Section 5.3.7.3 for related information.
Auxiliary Symbol Table Entry Fields
ti TIR), as defined in Section 5.2.8.1. rndx RNDX), as defined in Section 5.2.8.2. dnLow dnHigh isym stProc or stStaticProc symbols), this field is an index into the local symbols. It is also used as an index into the relative file descriptors. iss width count stBlock, scVariant).General Notes:
The fields dnLow, dnHigh, or width must all use either the 32-bit or 64-bit representation when used together. For example, an array dimension cannot be specified with a 32-bit dnLow and a 64-bit dnHigh.
typedef struct {
coff_uint fBitfield : 1;
coff_uint continued : 1;
coff_uint bt : 6;
coff_uint tq4 : 4;
coff_uint tq5 : 4;
coff_uint tq0 : 4;
coff_uint tq1 : 4;
coff_uint tq2 : 4;
coff_uint tq3 : 4;
} TIR, *pTIR;
SIZE - 4 bytes, ALIGNMENT - 4 bytes
Type Information Record Entry Fields
fBitfield continued bt tq0, tq1, tq2, tq3, tq4, tq5 tq fields must be used first, and all unneeded fields must be set to tqNil (0).bt) Constants|
Constant |
Value |
Description |
|
|
0 |
Undefined or void |
|
|
1 |
Address |
|
|
2 |
Character |
|
|
3 |
Unsigned character |
|
|
4 |
Short (16 bits) |
|
|
5 |
Unsigned short (16 bits) |
|
|
6 |
Integer (32 bits) |
|
|
7 |
Unsigned integer (32 bits) |
|
|
8 |
Long (32 bits) |
|
|
9 |
Unsigned long (32 bits) |
|
|
10 |
Floating point |
|
|
11 |
Double-precision floating point |
|
|
12 |
Structure or record |
|
|
13 |
Union |
|
|
14 |
Enumeration |
|
|
15 |
Defined by means of a user-defined type definition |
|
|
16 |
Range of values (for example, Pascal subrange) |
|
|
17 |
Sets (for example, Pascal) |
|
|
18 |
Currently unused |
|
|
19 |
Currently unused |
|
|
20 |
Indirect definition; following |
|
|
21 |
Fixed binary (for example, COBOL) |
|
|
22 |
Packed or unpacked decimal (for example, COBOL) |
|
|
25 |
Picture (for example, COBOL) |
|
|
26 |
Void |
|
|
27 |
Currently unused |
|
|
27 |
Scaled binary (for example, COBOL) |
|
|
28 |
Virtual function table (for example, C++) |
|
|
28 |
Array descriptor (for example, Fortran, Pascal) |
|
|
29 |
Class (for example, C++) |
|
|
30 |
Address |
|
|
30 |
Long (64 bits) |
|
|
31 |
Unsigned long (64 bits) |
|
|
31 |
Unsigned long (64 bits) |
|
|
32 |
Long long (64 bits) |
|
|
33 |
Unsigned long long (64 bits) |
|
|
34 |
Address (64 bits) |
|
|
34 |
Address (64 bits) |
|
|
35 |
Integer (64 bits) |
|
|
36 |
Unsigned integer (64 bits) |
|
|
37 |
Long double floating point (128 bits) |
|
|
38 |
Integer (64 bits) |
|
|
39 |
Unsigned integer (64 bits) |
|
|
41 |
64-bit range |
|
|
42 |
Procedure or function |
|
|
63 |
Symbol table checksum value stored in auxiliary record |
|
|
64 |
Number of basic type codes |
Table Notes:
btInt and btLong32 are synonymous.
btUInt and btULong32 are synonymous.
btLong, btLong64, btLongLong, btInt64, and btInt8 are synonymous.
btULong64, btULongLong, btUInt64, and btUInt8 are synonymous.
tq) Constants|
Constant |
Value |
Description |
|
|
0 |
No qualifier (placeholder) |
|
|
1 |
Pointer |
|
|
2 |
Procedure or function (obsolete) |
|
|
3 |
Array |
|
|
4 |
32-bit pointer; used with the |
|
|
5 |
Volatile |
|
|
6 |
Constant |
|
|
7 |
Reference |
|
|
8 |
Large array |
|
|
9 |
Reserved |
|
|
10 |
Reserved |
|
|
11 |
Reserved |
|
|
16 |
Number of type qualifier codes |
typedef struct {
coff_uint rfd : 12;
coff_uint index : 20;
} RNDXR, *pRNDXR;
SIZE - 4, ALIGNMENT - 4
Relative Symbol Record Fields
rfd ST_RFDESCAPE, defined as 0xfff in the header file cmplrs/stsupport.h. This value is used to indicate that the next auxiliary entry, interpreted as an isym, contains the index. index FDR.isymbase or FDR.iauxbase, depending on context.The string table is composed of two parts: the local string table and the external string table. In the on-disk symbol table, the external strings follow the local strings. The local string table is present only for objects created with full debugging information; it is removed if an object is locally stripped.
The storage format for the string table is a list of null-terminated character strings. It is correctly considered as one long character array, not an array of strings. Fields in the symbolic header and file headers represent string table sizes and offsets in bytes.
typedef struct {
coff_uint ppode_tag;
coff_uint ppode_len;
coff_ulong ppode_val;
} PPODHDR, *pPPODHDR;
SIZE - 16 bytes, ALIGNMENT - 8 bytes
See Section 5.3.3 for related information.
Optimization Symbol Entry Fields
ppode_tagppode_lenppode_val field.ppode_valppode_len is nonzero, this field is a relative file offset from the beginning of the current Per-Procedure Optimization Descriptor (PPOD) to the applicable data area. If ppode_len is zero, this field contains the data for the entry.|
Name |
Value |
Description |
PPODE_STAMP |
1 |
Version number of the PPOD stored in |
PPODE_END |
2 |
End of entries for this PPOD |
PPODE_EXT_SRC |
3 |
Extended source line information |
PPODE_SEM_EVENT |
4 |
Semantic event information. (Reserved for future use.) |
PPODE_SPLIT |
5 |
Split lifetime information. (Reserved for future use.) |
PPODE_DISCONTIG_SCOPE |
6 |
Discontiguous scope information. (Reserved for future use.) |
PPODE_INLINED_CALL |
7 |
Inlined procedure call information. (Reserved for future use.) |
PPODE_PROFILE_INFO |
8 |
Profile feedback information. |
Entries in the symbol table are primarily identified by the combination of their symbol type (st) and storage class (sc) values. Not all combinations are valid. Figure 5-3 indicates which combinations are currently in use.
Interpretation of storage class column labels:
Ab. scAbs RC. scRConst TC. scTlsCommon
BV. scBasedVar RD. scRData TD. scTlsData
Bi. scBits RI. scRegImage TU. scTlsUndefined
Bs. scBss Re. scRegister Ua. scUnallocated
Co. scCommon Rp. scReportDesc Un. scUndefined
Da. scData SB. scSBss US. scUserStruct
FD. scFileDesc SC. scSCommon Va. scVar
Fi. scFini SD. scSData VR. scVarRegister
If. scInfo SU. scSUndefined Vt. scVariant
In. scInit Sy. scSymref XD. scXData
Ni. scNil Te. scText
PD. scPData TB. scTlsBss
sc |ABBBC|DFFII|NPRRR|RRSSS|SSTTT|TTUUU|VVVX
st |bViso|aDifn|iDCDI|epBCD|UyeBC|DUanS|aRtD
-------------+-----+-----+-----+-----+-----+-----+----
stAlias | | X | | | | |
stBase | | X | | | | |
stBlock | X| X X | | X | X | | X
stConstant |X X |X X | X | X X| | |
stEnd | X| X X | | X | X | | X
stExpr | | | | | | |
stFile | | | | | X | |
stForward | | | | | | |
stGlobal | XX|X | XX | XXX|X XX|XX X |
stInter | | X | | | | |
stLabel |X X |X X X| XXX | X X| XX |X X | X
stLocal |X X |X X X| XXX |X X X| XX |X X |XX X
stMember | | X X | | X | | |
stModule | | | | | | |
stModview | | | | | | |
stNamespace | | X | | | | |
stNil | | | | | | |
stNumber | | | | | | |
stParam |X X |X X | XX |X X X| | X |XX
stProc | | X |X | | X | X |
stRegReloc | | | | | | |
stSplit | | | | | | |
stStaParam | | | | | | |
stStatic | XX|X X | XX | X X| X |X |
stStaticProc | | X X| | | X | |
stStr | | | | | | |
stTag | | X | | | | |
stType | | | | | | |
stTypedef | | X | | | | |
stUsing | | X | | | | |
stVirtBase | | X | | | | |
A symbol's type and class taken together determines interpretation of other fields in the symbol table entry. The same combination can be used for different purposes in different contexts. As a result, to understand the symbol entry, it also may be necessary to access type information in the auxiliary table or the source language information in the file descriptor.
The contents of the value and index fields for each combination, with a brief explanation of the symbol's use, are described in the following list of combinations. For many combinations, greater detail can be found in Section 5.3.7 and Section 5.3.8 .
stGlobal,sc(S)Data/(S)Bss/RData/Rconst
value field is the symbol's address.
index field is an auxiliary table index or indexNil (if the auxiliary table is not present).
stGlobal,scTlsData/TlsBss
value field is the offset from the base of the object's TLS region.
index field is an auxiliary table index or indexNil (if the auxiliary table is not present).
stGlobal, sc(S)Common/TlsCommon
value field is the symbol's size in bytes.
index field is an auxiliary table index or indexNil (if the auxiliary table is not present).
stGlobal, sc(S)Undefined/TlsUndefined
value field is zero in linked objects. In relocatable objects, the value field is ignored. (Some compilers store the size in bytes of the global variable in the value field.)
index field is an auxiliary table index or indexNil (if the auxiliary table is not present).
stStatic, sc(S)Data/(S)Bss/RData/Rconst
value field is the symbol's address.
index field is an auxiliary table index.
stStatic, scTlsData/TlsBss
stStatic, scCommon
value field is zero.
index field is an auxiliary table index.
stStatic, scInfo
value field is zero.
index field is an auxiliary table index.
stParam, scAbs
value field is an offset from the virtual frame pointer.
index field is an auxiliary table index.
stParam, scRegister
value field is the number of the register containing the parameter.
index field is an auxiliary table index.
stParam, scVar
value field is an offset from the virtual frame pointer to the parameter's address.
index field is an auxiliary table index.
stParam, scVarRegister
value field is the register number containing the address of the parameter.
index field is an auxiliary table index.
stParam, scInfo
value field is zero.
index field is an auxiliary table index.
stParam, sc(S)Data/(S)Bss/Rconst/Rdata
value field is the address of the parameter.
index field is an auxiliary table index.
stParam, scUnallocated
value field is zero.
index field is an auxiliary table index.
stLocal, scAbs
value field is an offset from the virtual frame pointer.
index field is an auxiliary table index.
stLocal, scRegister
value field is the number of the register containing the variable.
index field is an auxiliary table index.
stLocal, scVar
value field is an offset from the virtual frame pointer to the symbol's address.
index field is an auxiliary table index.
stLocal, scVarRegister
value field is the register number containing the address of this variable.
index field is an auxiliary table index.
stLocal, scUnallocated
value field is zero.
index field is an auxiliary table index.
stLocal, scText/Init/Fini/(S)Data/(S)Bss/Rconst/Rdata/TlsData/TlsBss
indexNil.
.text or .init).stLabel, scAbs
stLabel, scText/Init/Fini/(S|X|P|R)Data/(S)Bss/Rconst/TlsData/TlsBss
value field is the label's value (an address).
index field is indexNil.
stLabel, scUnallocated
value field is zero.
index field is indexNil.
stProc, scNil
value field is zero.
index field is indexNil.
stProc, scText
value field is the procedure's address.
index field is an auxiliary table index.
index field is indexNil. stProc, scUndefined
value field is zero.
index field is indexNil.
stProc, scInfo
value field contains a value of:
-1 (a procedure with no code)
-2 (a function prototype or function pointer definition)
index field is an auxiliary table index.
value field is used to distinguish among these possibilities.stBlock, scText
value field depends on context:
stBlock,scText symbol following an stProc,scText symbol, the value is the byte offset from the procedure's address to the address of the first instruction beyond the end of the procedure's prologue.
index field is the local symbol index of the symbol following the matching stEnd. If this is the first stBlock,scText following an stProc,scText for an alternate entry point, the index field will be set to indexNil because the symbol will not have a matching stEnd symbol.
stBlock, scInfo
value field depends on context:
index field is the local symbol index of the symbol following the matching stEnd.
stBlock,scVariant scope. This symbol is also used to define the block scope of a procedure with no code.stBlock, scCommon
value field is the size of the common block in bytes.
index field is the local symbol index of the symbol following the matching stEnd.
stBlock, scVariant
value field is the local symbol index of the structure member whose value determines which variant range is used.
index field is a the local symbol index of the symbol following the matching stEnd.
stBlock, scFileDesc/scReportDesc
value field is zero.
index field is a the local symbol index of the symbol following the matching stEnd.
stEnd, scText
value field depends on the type of scope it is ending. It is:
index field is the local symbol index of the matching stBlock, stProc, or stFile.
stEnd, scInfo
value field is zero.
index field is a the local symbol index of the matching stBlock or stNamespace.
stNamespace, this symbol ends a namespace definition.stEnd, scCommon
value field is zero.
index field is the local symbol index of the matching stBlock.
stEnd, scVariant
value field is the same as that of the matching stBlock.
index field is the local symbol index of the matching stBlock.
stEnd, scFileDesc/scReportDesc
value field is zero.
index field is the local symbol index of the matching stBlock.
stMember, scInfo
value field depends on the symbol's data type:
index field is an auxiliary table index.
stMember, scFileDesc/scReportDesc
value field is zero or one, depending on whether the symbol is local or external, respectively.
index field is an auxiliary table index.
stTypedef, scInfo
value field depends on the purpose of this symbol:
index field plus one.index field is an auxiliary table index.
stTag, scInfo symbol for an empty C++ class or structure. stFile, scText
value field is zero.
index field is the local symbol index of the symbol following the matching stEnd.
stStaticProc, scText
value field is the procedure's address.
index field is an auxiliary table index.
stStaticProc, scInit/Fini
value field is the procedure address.
index field is an auxiliary table index.
__istart and __fstart, which are inserted by the linker.stConstant, scInfo
value field is the value of the constant.
index field is an auxiliary table index.
PARAMETER).stConstant, scAbs
value field is the value of the constant.
index field is an auxiliary table index.
PARAMETER).stConstant, sc(S)Data/(S)Bss/RData/Rconst
value field is the symbol's address.
index field is an auxiliary table index.
stBase, scInfo
value field is the offset of the base class relative to a derived class.
index field is an auxiliary table index.
stVirtBase, scInfo
value field is an index (starting at 1) of the base class run-time description in the virtual base class table. See Section 5.3.8.6.2.
index field is an auxiliary table index.
stTag, scInfo
value field is zero.
index field is an auxiliary table index.
stInter, scInfo
value field is zero.
index field is an auxiliary table index.
stNamespace, scInfo
value field is zero.
index field is the local symbol index of the symbol following the matching stEnd.
stUsing, scInfo
value field is zero.
index field is an auxiliary table index.
stAlias, scInfo
value field is zero.
index field is an auxiliary table index.
Combinations may be valid in the local symbol table, the external symbol table, or both. Table 5-7 shows which combinations are valid in which table, based on the symbol type value and also the storage class value where necessary. Only combinations previously specified as valid apply where the storage class value is shown as a wildcard value with the character '*'.
|
|
External Symbol Table |
Local Symbol Table |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table Notes:
scSCN = scData, scSData, scBss, scSBss, scRConst, scRData, scInit, scFini, scText, scXData, scPData, scTlsData, scTlsBss, scTlsInitDifferent levels of symbolic information can be stored with an object file. Compilers often provide options that allow the user to choose the desired level of symbolic information for their program. This choice may be influenced by size considerations and debugging needs. A trade-off exists between the benefit of saving space in the object file and the amount of information available to tools that consume symbolic information.
It is also possible to change the amount of symbolic information present in a program that has already been compiled and linked. Information can be added or deleted. Two of the most common and useful operations are locally stripping and fully stripping the symbol tables in executable files. Tools that modify linked executables, such as instrumentation tools and code optimizers, may rewrite parts of the symbol table to reflect changes that they made.
The representation of symbolic information supported by compilers can be broken down into four levels:
These levels correspond to the system compiler switches -g0 (minimal), -g1 (limited), -g2 (full), and
-g3 (optimized). Table 5-8 shows the symbol table sections that are produced by system compilers at each compilation level.
|
Symbol Table Section |
Compilation Level |
|||
|
Minimal |
Limited |
Full |
Optimized |
|
|
Symbolic header |
Yes |
Yes |
Yes |
Yes |
|
File Descriptors |
Yes |
Yes |
Yes |
Yes |
|
External Symbols |
Yes |
Yes |
Yes |
Yes |
|
External Strings |
Yes |
Yes |
Yes |
Yes |
|
Procedure Descriptors |
Yes |
Yes |
Yes |
Yes |
|
Line Numbers |
No |
Yes |
Yes |
Yes |
|
Relative File Descriptors |
No |
No |
Yes |
Yes |
|
Optimization Symbols |
No |
Partial |
Yes |
Yes |
|
Local Symbols |
No |
Partial |
Yes |
Yes |
|
Local Strings |
No |
Partial |
Yes |
Yes |
|
Auxiliary Symbols |
No |
Partial |
Yes |
Yes |
The minimal level of symbolic information that may be produced during compilation includes only the symbol information required for the linker to function properly. This includes external symbol information that is needed to perform symbol resolution and relocation.
If the limited level of symbolic information is requested, line number entries are generated, but the auxiliary table will contain only external symbol entries. Again, external symbol and procedure descriptors are available. In addition, local symbols for procedures (and the corresponding auxiliary symbols, optimization symbols, and local strings) are present. Limited symbolic information is sufficient to meet the needs of profiling tools. The information present at this level is a subset of that required for full debugger support.
If full symbolic information is included, all symbol table section are produced in full. This level enables full debugging support with complete type descriptions for local and external symbols. Optimization is disabled.
Optimized symbolic information is designed to balance the aims of performance and debugging capabilities. This level supplies the same information as the full debugging option, but it also allows all compiler optimizations. As a result, some of the correlation is lost between the source code and the executable program.
On Tru64 UNIX systems, users can choose to compile their programs with any one of the four levels of symbolic information. The options -g0, -g1, and -g2 specify increasing levels of symbolic information. The system compiler's default is to produce the minimal level (-g0). Currently, debugging of optimized code (-g3) is not fully supported. See cc(1) for more details.
Objects can be produced with only global symbolic information stored in the symbol table. Selection of the -x option causes the linker to create a locally-stripped object. Reasons for stripping local symbolic information include reducing file size and limiting the amount of symbolic information available to end users of an application.
A locally-stripped object is very similar to an object produced with minimal symbolic information (see Section 5.3.1.1). The difference is the consolidation of file descriptors, which the linker does only for locally-stripped objects.
In a locally-stripped image, the file descriptors are included solely for the purpose of identifying source file languages. One file descriptor is present for each source language involved in the compilation. These file descriptors will have their adr field set to addressNil indicating the file descriptors cannot be used to identify text addresses.
The procedure descriptor table is present in full but is rearranged to group procedures by source language. All procedure descriptors for procedures written in a particular source language are thus contiguous, and they reflect the file descriptor's information.
External symbols are also present in a locally-stripped image. The file indices (ifd field) of the external symbols are updated to identify the generic file descriptor for the appropriate source language. The index fields are set to zero to indicate that no type information is available. External symbols with the storage class scNil are removed. These are debugging symbols that are not normally produced for minimal symbol tables.
Limited debugging is possible with locally-stripped objects. Because the procedure descriptors are retained, stack traces are possible. External symbol information can also be viewed, and language-dependent handling of symbols (for example, C++ name demangling) is preserved.
A linked executable file can be locally stripped at any time after its creation using the ostrip -x option. The output is the same as described above. This operation may also alter the raw data of the .comment section. See Chapter 7 for details.
Executable files may be fully stripped at any time after creation using either the strip command or the ostrip -s command. Stripping an executable will result in complete removal of the symbol table, including the symbolic header. The file header fields f_symptr and f_nsyms are set to zero to indicate that the file has been stripped.
This operation may also alter the raw data of the .comment section. See Chapter 7 for details.
The final executable image for a program bears little resemblance to the source code files from which it was created. One of the principal functions of the symbol table is to track the relationship between the two so that the debugger is able to describe the resulting program in a way that the programmer can recognize.
Much of the complication of source information stems from the "include" system. When a compilation involves several source files, there may be duplication of the header files included in each source file, or of the source files themselves. To avoid repetition of header file information in the linked object, the linker merges the input objects' included files wherever possible. Compilers mark file descriptors as mergeable or unmergeable. The linker then examines the input file descriptors and performs the merge whenever possible.
The linker considers two file descriptors to be mergeable if all of the following criteria are met:
fMerge bit is set in both (marked as mergeable by compiler).
btChecksum.
btChecksum and they are identical. The role of the relative file descriptor (RFD) tables is to track file-relative information after merging. A relative file descriptor table entry maps the index of each file at compile time to its index after linking. After linking, local or auxiliary symbols must be accessed through the RFD table to obtain the updated file descriptor index. This mechanism is necessary because the indices in the local symbol table are not updated when files are merged.
Figure 5-4 is an example of the use of the relative file descriptor table.
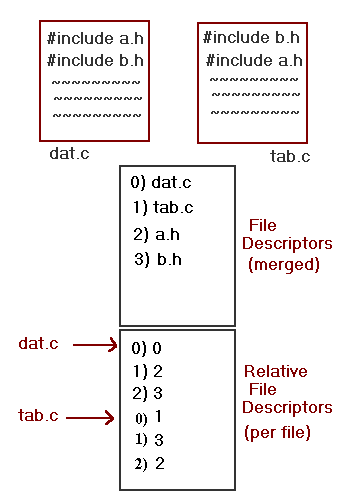
For a symbol reference composed of a file index and symbol index (offset within file), the relative file descriptor table is used as follows:
See Section 5.3.7.3 for the representation of relative indices in the auxiliary symbol table.
For a debugger to be effective, a connection must be made between high-level-language statements in source files and the executable machine instructions in object files. Line number entries map executable instructions to source lines. This mapping allows a debugger to present to a programmer the line of source code that corresponds to the code being executed. The line number information is produced by the compiler and should be rewritten if an application such as an instrumentation tool or an optimizer modifies code.
In V3.13 of the Tru64 UNIX symbol table, line number information is emitted in two forms, one found in the line number table and one in the optimization symbol table. (Section5.3.3 describes the structure of the optimization symbol table.) The line number information found in the optimization symbol table is referred to as "extended source location information". This is a new form of line number information introduced in V3.13 symbol tables. The new line number information augments the information in the line number table. If both forms of line number information are present in an object the extended source line information will only be present for procedures that cannot be described adequately by entries in the line number table.
Line number information is generated for each source file that contributes executable code to a program. Within each source file, line numbers are organized by procedure, in the order of appearance in the file. The line number symbol table section is produced only when a program is compiled with limited or greater symbolic information (see Section 5.3.2.2).
Figure 5-5 illustrates of the organization of the line number table.
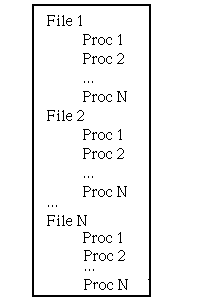
The order outlined in Figure 5-5 is not guaranteed to match the ordering of file descriptors or procedure descriptors in those tables. To determine the bounds of the line number table entries for a specific procedure, fields in the associated file descriptor and procedure descriptors must be used. The starting offset for a procedure's line table entries is calculated directly from these fields. The ending offset can only be determined by finding the starting offset of the next procedure's entries in the line number table. An algorithm to identify the starting and ending line table offsets for a procedure follows.
IPD = index-of-procedure
IFD = index-of-file-containing-procedure
if (FDR[IFD].cbLine == 0 or
(PDR[IPD].iline == ilineNil ))
/* No line information for this procedure */
START_FILE_OFFSET = FDR[IFD].cbLineOffset
END_FILE_OFFSET = START_FILE_OFFSET + FDR[IFD].cbLine
START_PROC_OFFSET = START_FILE_OFFSET + PDR[IPD].cbLineOffset
NEXTIPD = -1
for (I = 0; I < FDR[IFD].cpd; I++)
IPD2 = FDR[IFD].ipdFirst + I
if (IPD2 != IPD and
PDR[IPD2].iline != ilineNil and /* No lines */
PDR[IPD2].lnHigh != -1 and /* Alt entry */
PDR[IPD2].cbLineOffset > PDR[IPD].cbLineOffset)
if (NEXTIPD == -1 or
PDR[PID2].cbLineOffset < PDR[NEXTIPD].cbLineOffset)
NEXTIPD = IPD2
if (NEXTIPD == -1)
/* IPD is the last procedure with line numbers in the file */
END_PROC_OFFSET = END_FILE_OFFSET
else
END_PROC_OFFSET = START_FILE_OFFSET + PDR[NEXTIPD].cbLineOffset
Alternate entrypoints have a starting line number, but they have no specific ending line number. Procedure descriptors for a procedure and each of its associated alternate entrypoints share a common end offset in the line number table. See Section 5.3.6.7 for more information on alternate entrypoints.
The line number table has two forms. The "packed" form is used in the object file. The "expanded" form is a more useful representation to programmers and can be derived algorithmically (or by API) from the packed form.
The packed line numbers are stored as bytes. Each packed entry within the single byte value consists of two parts: count and delta. The count is the number of instructions generated from a source line. The delta is the number of source lines between the current source line and the previous one that generated executable instructions.
Figure 5-6 shows how these two values are represented.
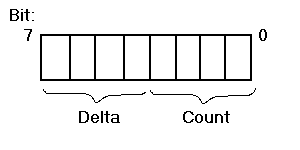
The four-bit count is interpreted as an unsigned value between 1 and 16 (0 means 1, 1 means 2, and so forth). A zero value would be wasted when no instructions are generated for a source line and, as a result, no line number entry will exist for that line.
The four-bit delta is interpreted as a signed value in the range -7 to +7. The reason for this is that code generators may produce instructions that are not in the same order as the corresponding source lines. Therefore, the offset to the "next" source line may be a forwards or backward jump.
Either of these quantities may fall outside the permissible range. For a delta outside the range, an extended format exists (as shown in Figure 5-7).
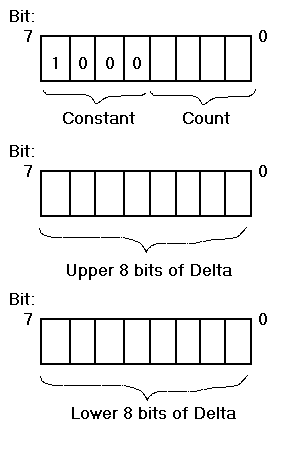
For a count outside the range, one or more additional entries follow, with the delta set to zero.
If both fields are out of range, the delta is handled first. An extended-format delta representation is followed by an entry with the delta bits set to zero and the remainder of the count contained in the count value.
The packed line number format can be expanded to produce the instruction-to-source-line mapping that is needed for debugging. An algorithm to accomplish this transformation for a given procedure follows. The expanded line number array has a source line number entry for each instruction in the given procedure. The address of the first entry is the address recorded in the PDR.adr field. Subsequent entries correspond to contiguous sequential instruction addresses.
START_PROC_OFFSET = offset-of-procedure's-entries-in-line-table
END_PROC_OFFSET = offset-of-next-procedure's-line-table-entries
PACKED = HDRR.cbLineOffset + START_PROC_OFFSET
CURRENTLINE = PDR.lnLow
EXPANDED = ALLOCATE(number-of-instructions-in-procedure)
for (I = 0;
I < (END_PROC_OFFSET - START_PROC_OFFSET)/sizeof(*PACKED);
I++)
COUNT = (unsigned)(PACKED[0] & 0x0F) + 1
DELTA = (signed)(PACKED[0] & 0xF0) >> 4
if (DELTA == (signed)0x8) /* Extended delta */
DELTA = (signed)((PACKED[2] << 8) | PACKED[1])
PACKED += 2
else
PACKED += 1
if (current-offset-matches-offset-of-alternate-entry)
CURRENTLINE = PDR.lnLow of alternate entry
CURRENTLINE += DELTA
while (COUNT-- > 0)
*EXPANDED = CURRENTLINE
EXPANDED++
The following source listing of a file named lines.c provides an example that shows how the compiler assigns line numbers:
1 #include <stdio.h>
2 main()
3 {
4 char c;
5
6 printf("this program just prints input\n");
7 for (;;) {
8 if ((c =fgetc(stdin)) != EOF) break;
9 /* this is a greater than 7-line comment
10 * 1
11 * 2
12 * 3
13 * 4
14 * 5
15 * 6
16 * 7
17 */
18 printf("%c", c);
19 } /* end for */
20 } /* end main */
The compiler generates line numbers only for the lines 2, 6, 8, 18, and 20; the other lines are either blank or contain only comments.
Table 5-9 shows the packed entries' interpretation for each source line.
|
Source Line |
LINER contents |
Interpretation |
|
2 |
|
Delta 0, count 4 |
|
6 |
|
Delta 4, count 5 |
|
8 |
|
Delta 2, count 10 |
|
18 1 |
|
Delta 10, count 9 |
|
19 |
|
Delta 1, count 1 |
|
20 |
|
Delta 1, count 5 |
Table Note:
The compiler generates the following instructions for the example program:
[lines.c: 2] 0x0: ldah gp, 1(t12) [lines.c: 2] 0x4: lda gp, -32592(gp) [lines.c: 2] 0x8: lda sp, -16(sp) [lines.c: 2] 0xc: stq ra, 0(sp) [lines.c: 6] 0x10: ldq a0, -32720(gp) [lines.c: 6] 0x14: ldq t12, -32728(gp) [lines.c: 6] 0x18: jsr ra, (t12), printf [lines.c: 6] 0x1c: ldah gp, 1(ra) [lines.c: 6] 0x20: lda gp, -32620(gp) [lines.c: 8] 0x24: ldq a0, -32736(gp) [lines.c: 8] 0x28: ldq t12, -32744(gp) [lines.c: 8] 0x2c: jsr ra, (t12), fgetc [lines.c: 8] 0x30: ldah gp, 1(ra) [lines.c: 8] 0x34: lda gp, -32640(gp) [lines.c: 8] 0x38: and v0, 0xff, t0 [lines.c: 8] 0x3c: stq v0, 8(sp) [lines.c: 8] 0x40: xor t0, 0xff, t0 [lines.c: 8] 0x44: bne t0, 0x6c [lines.c: 18] 0x48: ldq t2, 8(sp) [lines.c: 18] 0x4c: sll t2, 0x38, t2 [lines.c: 18] 0x50: sra t2, 0x38, a1 [lines.c: 18] 0x54: ldq a0, -32752(gp) [lines.c: 18] 0x58: ldq t12, -32728(gp) [lines.c: 18] 0x5c: jsr ra, (t12), printf [lines.c: 18] 0x60: ldah gp, 1(ra) [lines.c: 18] 0x64: lda gp, -32688(gp) [lines.c: 19] 0x68: br zero, 0x24 [lines.c: 20] 0x6c: bis zero, zero, v0 [lines.c: 20] 0x70: ldq ra, 0(sp) [lines.c: 20] 0x74: lda sp, 16(sp) [lines.c: 20] 0x78: ret zero, (ra), 1 [lines.c: 20] 0x7c: call_pal halt
After applying the given algorithm, the following instruction-to-source mapping (formatted instruction number. source line number) is obtained:
0. 2 1. 2 2. 2
3. 2 4. 6 5. 6
6. 6 7. 6 8. 6
9. 8 10. 8 11. 8
12. 8 13. 8 14. 8
15. 8 16. 8 17. 8
18. 18 19. 18 20. 18
21. 18 22. 18 23. 18
24. 18 25. 18 26. 19
27. 20 28. 20 29. 20
30. 20 31. 20
Header files included in an object have no associated line numbers recorded in the symbol table. Line number information for included files containing source code is not supported.
The line number table does not correctly describe optimized code or programs with untraditional source files, resulting in images that are difficult to debug. Extended Source Location Information (ESLI) is intended to provide more information to enable debugging of optimized programs, including PC and line number changes, file transitions, and line and column ranges. ESLI is essentially a superset of the older line number table.
ESLI is stored in the optimization symbols section. This information is accessible on a per-procedure basis from the procedure descriptors. See Section 5.3.3 for more detail on accessing information in the optimization symbols section.
ESLI is a byte stream that can be interpreted in two modes: data mode or command mode. Currently, two formats are defined for data mode. These are designated as "Data Mode 1" and "Data Mode 2". Additional data modes may be defined as needed.
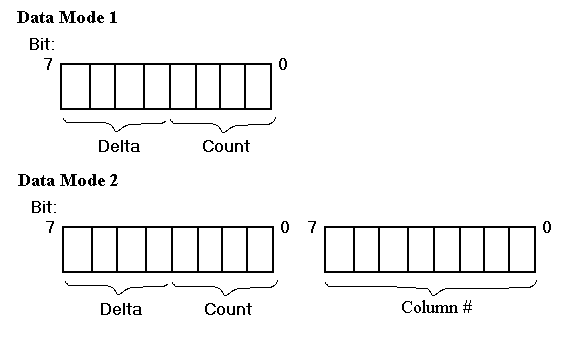
Data Mode 1 is the initial mode for a procedure's ESLI. Data Mode 1 is identical to the packed line number format with the exception of the interpretation of the delta PC escape value '1000' (which indicates a switch to command mode).
In Data Mode 2, each entry consists of two bytes. The first byte is identical to the encoding and interpretation of Data Mode 1. The second byte is an absolute column number (from 0 to 255), where column number 0 indicates that column information is missing or not meaningful for this entry. The escape from Data Mode 2 to command mode consists of a delta PC escape value set to '1000' and column number set to 0.
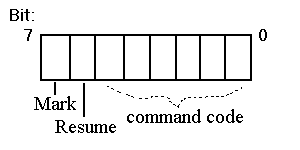
In command mode, each byte is either a command or a command parameter. For a command byte, the low-order six bits are a command code, and the two high bits are used as flags, as shown in Figure 5-9. The "mark" flag, if set, announces that a new state has been established. Several commands may be required to fully describe a new state. The "resume" flag, if set, indicates the end of command mode. The next byte following a command with "resume" set will be a data mode byte. The same data mode that was in effect prior to the escape to command mode will be resumed. See Table 5-10 for a complete list of commands.
Command parameters are stored in LEB (Little Endian Byte) 128 format. See Section 1.4.6 for a description of this data representation. PC deltas are always expressed as machine instruction offsets and must be scaled by the size of a machine instruction before adding to the current PC. No other deltas need to be scaled.
Table 5-10 shows how to interpret the bytes in command mode. These definitions can be found in the system header file linenum.h.
|
Name |
Value |
Number of Parameters |
Type of Parameters |
|
|
1 |
1 |
SLEB |
|
|
2 |
1 |
SLEB |
|
|
3 |
1 |
LEB |
|
|
4 |
1 |
LEB |
|
|
5 |
1 |
LEB |
|
|
6 |
2 |
SLEB, SLEB |
|
|
7 |
3 |
SLEB, SLEB, LEB |
|
|
8 |
1 |
LEB |
|
|
9 |
2 |
LEB, LEB |
ADD_PC ADD_LINE SET_COL SET_FILE set_line command.SET_DATA_MODE 1 and 2. Additional data modes may be defined in future releases. ADD_LINE_PCADD_LINE_PC_COL SET_LINE SET_LINE_COL A tool reading the ESLI must maintain the current PC value, file number, line number, and column. Taken together, these four values represent the current "state". Consumers must also keep track of the mode in effect to interpret the data properly. The following example shows the instructions for consuming ESLI for one procedure.
MODE = data mode 1
FILE = current file
LINE = PDR.lnLow
COLUMN = 0
PC = PDR.adr
STATE_TABLE++ = (FILE,LINE,COLUMN,PC)
ESLI = GET_ESLI(PDR.iopt)
for ppode_len bytes of ESLI do
if (MODE == data mode 1 or MODE == data mode 2)
if (ESLI.delta == escape)
PUSH_MODE(MODE)
MODE = command mode
else
PC += 4 * ESLI.delta
LINE += COUNT + 1
if (MODE == data mode 1)
STATE_TABLE++ = (FILE,LINE,COLUMN,PC)
ESLI++
if (MODE == data mode 2)
COLUMN = ESLI++
STATE_TABLE++ = (FILE,LINE,COLUMN,PC)
if (MODE == command mode)
read all parameters
update FILE, LINE, COLUMN and PC as required
if (mark flag set)
STATE_TABLE++ = (FILE,LINE,COLUMN,PC)
if (resume flag set)
MODE = POP_MODE()
ESLI += number-of-bytes-read
Data encoded in ESLI can be represented in tabular format. The PC value and file, line and column numbers can be stored as a state table. The following example shows how to build this state table.
In this example ESLI will record line numbers for a routine that includes text from a header file.
Source listing for line1.c:
1 /* ESLI example using included source lines */
2
3 main() {
4 char *msg;
5
6 msg = (char *)0;
7
8 #include "line2.h"
9
10 printf("%s", msg);
11 }
Source listing for line2.h
1 msg = (char *)malloc(20); 2 /* 3 * 4 * 5 * 6 * 7 * 8 * 9 * 10 */ 11 strcpy(msg, "Hello\n");
The compiler generates the following instructions for the example program:
main: [line1.c: 3] 0x1200011d0: ldah gp, 8192(t12) [line1.c: 3] 0x1200011d4: lda gp, 28336(gp) [line1.c: 3] 0x1200011d8: lda sp, -16(sp) [line1.c: 3] 0x1200011dc: stq ra, 0(sp) [line1.c: 3] 0x1200011e0: stq s0, 8(sp) [line1.c: 6] 0x1200011e4: bis zero, zero, s0 [line2.h: 1] 0x1200011e8: bis zero, 0x14, a0 [line2.h: 1] 0x1200011ec: ldq t12, -32560(gp) [line2.h: 1] 0x1200011f0: jsr ra, (t12) [line2.h: 1] 0x1200011f4: ldah gp, 8192(ra) [line2.h: 1] 0x1200011f8: lda gp, 28300(gp) [line2.h: 1] 0x1200011fc: bis zero, v0, s0 [line2.h: 11] 0x120001200: bis zero, s0, a0 [line2.h: 11] 0x120001204: lda a1, -32768(gp) [line2.h: 11] 0x120001208: ldq t12, -32600(gp) [line2.h: 11] 0x12000120c: jsr ra, (t12) [line2.h: 11] 0x120001210: ldah gp, 8192(ra) [line2.h: 11] 0x120001214: lda gp, 28272(gp) [line1.c: 10] 0x120001218: ldq_u zero, 0(sp) [line1.c: 10] 0x12000121c: lda a0, -32760(gp) [line1.c: 10] 0x120001220: bis zero, s0, a1 [line1.c: 10] 0x120001224: ldq t12, -32552(gp) [line1.c: 10] 0x120001228: jsr ra, (t12) [line1.c: 10] 0x12000122c: ldah gp, 8192(gp) [line1.c: 10] 0x120001230: lda gp, 28244(gp) [line1.c: 11] 0x120001234: bis zero, zero, v0 [line1.c: 11] 0x120001238: ldq ra, 0(sp) [line1.c: 11] 0x12000123c: ldq s0, 8(sp) [line1.c: 11] 0x120001240: lda sp, 16(sp) [line1.c: 11] 0x120001244: ret zero, (ra)
The ESLI and its interpretation for the generated code is shown in the following table.
|
ESLI bytes (hex) |
Mode |
Command |
State |
|||||
|
Code |
M |
R |
PC (hex) |
F |
L |
C |
||
|
Initial State |
Data1 |
|
|
|
|
|||
|
|
Data1 |
|
|
|
|
|||
|
|
Data1 |
|
|
|
|
|||
|
|
Data1 |
Escape |
||||||
|
|
Cmd |
|
|
|||||
|
|
Cmd |
|
X |
|
||||
|
|
Data1 |
|
|
|
|
|||
|
|
Data1 |
Escape |
||||||
|
|
Cmd |
|
X |
|
|
|
|
|
|
|
Cmd |
|
|
|||||
|
|
Cmd |
|
X |
|
||||
|
|
Data1 |
|
|
|
|
|||
|
|
Data1 |
|
|
|
|
|||
The handling of alternate entry points differs from the handling of main entry points. Procedure descriptors for alternate entry points are identified by a PDR.lnHigh value of -1. If the PC for an instruction maps to an alternate entry point, the following steps should be taken:
PDR.lnHigh is not -1).
PDR.adr field of the alternate entry's procedure descriptor.The optimization symbols section gives individual producers and consumers the ability to communicate information about any aspect of the object file, in any form they choose. New information can be generated at any time with minimal coordination between all producers and consumers. In V3.13 of the symbol table, the optimization section may include extended source location information (see Section 5.3.2.2).
The optimization section is organized on a per-procedure basis. Each procedure descriptor has a pointer to the optimization symbols in the field PDR.iopt. If no optimization symbols are associated with the procedure, the field contains ioptNil. Otherwise, it contains the index of the first optimization symbol entry for this procedure. Consumers should access the optimization symbols through the procedure descriptors. The optimization section is not present in a locally-stripped object.
This section consists of a sequence of zero or more Per-Procedure Optimization Descriptions (PPODs), as shown in Figure 5-10. Each PPOD's internal structure consists of two parts:
PPOD entry can be found in Section 5.2.10.
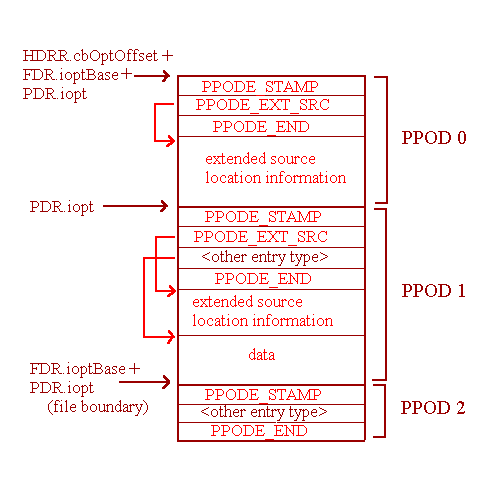
This section has the following alignment requirements:
PPOD.Object file producers must produce either an empty optimization symbols section or a valid one. An empty one has the symbolic header fields cbOptOffset and ioptMax set to zero. If an optimization section is present, but a particular file does not contribute to it, the file descriptor field copt is set to zero. In this case, all procedure descriptors belonging to the file must have their iopt fields set to ioptNil.
Tools that both read and write object files must consume a valid optimization symbols section (if present in the input file) and produce an equivalent and valid section in its output file. If a tool does not know how to process the section contents, the section must be omitted from the output file. If a tool does know how to process portions of the optimization symbols, those portions may be modified and the rest should be removed. As usual, the linker is a special case. It concatenates input optimization symbols sections into one output section without reading or modifying any of the entries.
The format and flexible nature of this section are similar by design to the .comment section. The structures are the same size and contain the same fields (with different names), and the rules of navigation are the same. The primary difference is that the optimization section is broken down by procedure; whereas, the comment section must be treated as a whole.
The symbol table contains information that debuggers must interpret to find symbols at run time. This section describes the information that the static symbol table structures provides. Algorithms for determining run-time symbol addresses are included.
A stack frame is a run-time memory structure that is created whenever a procedure is called. The Calling Standard for Alpha Systems specifies the stack frame format and related code requirements. This section explains how to interpret procedure descriptor fields related to the stack frame.
Two types of stack frames are supported: fixed-size frames and variable-size frames. The variable frame format is used for procedures that dynamically allocate memory and for those with very large frames. Figure 5-11 shows a fixed-size frame and Figure 5-12 shows a variable-sized frame.
From the procedure descriptor, you can determine which type of stack frame the procedure has. The field PDR.framereg stores the frame pointer register number. If this field has a value of 30 ($sp), the stack frame is a fixed-size frame. If it has a value of 15 ($fp), the stack frame is a variable-size frame.
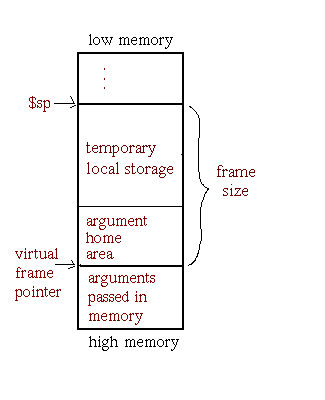
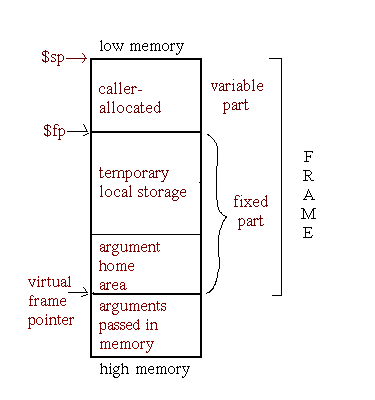
For both types of stack frames, the value of PDR.frameoffset is the size of the fixed part of the stack frame. In the case of a fixed-size frame, it is the entire frame size. For a variable-sized frame, the entire frame size cannot be determined from the symbol table. The code may dynamically increase and decrease the size of the frame multiple times during procedure execution.
The virtual frame pointer represents the contents of the frame pointer register at procedure entry, prior to prologue execution. The (real) frame pointer is the contents of the frame pointer register after prologue execution. The difference between the virtual and real frame pointer values is the fixed frame size, which is subtracted from the $sp contents during the procedure prologue. Note that stack offsets recorded in the symbol table are relative to the virtual frame pointer, not the real value used at run time.
The contents of the frame pointer register at are used at run time as the base address for accessing data, such as parameters and local variables, on the stack. See Section 5.3.4.3 for details.
The PDR.adr is reliably updated by the linker starting with version V3.13 of the symbol table. To determine the procedure start address for a given PDR in prior versions of the symbol table, the following algorithm is recommended:
if (HDRR.vstamp >= 0x30D || PDR.isym == isymNil)
return(PDR.adr)
else
foreach FDR in HDRR
foreach PDR in FDR
if PDR matches
if (FDR.csym == 0) /* Use external symbol */
return (EXTR[PDR.isym].asym.value)
else /* Use local symbol */
return (SYMR[FDR.isymbase + PDR.isym].value)
If local symbol information is present for the given PDR, the isym field identifies the local symbol table entry that contains the start address of the procedure. If no local symbol information is present, the isym field identifies the external symbol table entry containing the start address of the procedure. If no symbol information is present for the PDR, the isym field is set to isymNil and the adr field will contain a reliable start address.
Local variables and parameters may be stored in registers or on the stack. Those stored in registers (identified by a storage class of scRegister) do not have addresses. For local variables and parameters with addresses, this section explains how to calculate their run-time locations from the symbol table information.
To calculate the run-time address for a local variable (stLocal) based on its symbol table value:
Frame pointer - PDR.localoff + SYMR.value
To calculate the run-time address for a parameter (stParam) based on its symbol table value:
Frame pointer - argument_home_area_size + SYMR.value
The argument home area is a portion of the stack frame designated for parameter storage. See Figure 5-11 for an illustration. For historical reasons, the size of this area is always 48 bytes.
The calculations above must be performed at run time when the actual frame pointer value is known. Note that the value becomes valid only after the procedure prologue has executed.
To calculate the locations based on static information, convert the symbol's value to an offset from the real frame pointer:
Local:
PDR.frameoffset - PDR.localoff + SYMR.value
Parameter:
PDR.frameoffset - 48 + SYMR.value
The resulting offsets are always positive values because the frame pointer contains the address of the lowest memory in the fixed part of the stack frame at run time.
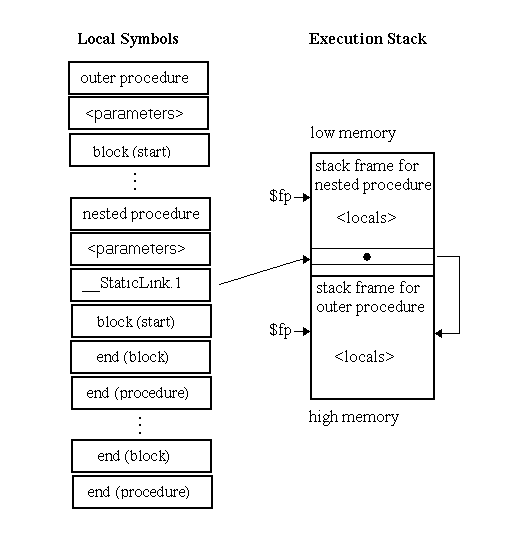
An uplevel link is the real frame pointer of an ancestor of a nested routine. The routine nesting may be a feature of the language (such as Pascal), or the nesting may occur in optimized code which has been decomposed for parallel execution into smaller routines. Uplevel links provide debuggers a method of finding all local symbols associated with the ancestor routine.
When a procedure is passed a static link, that static link will be represented within the scope of the procedure definition as a local automatic symbol with a special name beginning with "__StaticLink.". The lifetime of this symbol begins after the procedure prologue has been executed.
The static link symbol will occur between the procedure's parameter definitions and the first stBlock symbol.
The full name of the symbol will be "__StaticLink." followed by a positive decimal integer with no leading zeros. This integer value identifies the number of levels up the ancestor tree the static link points to.
For example, if the name is "__StaticLink.3" it will contain the static link of the procedure in which it is defined, and that procedure's static link points to a stack frame that is three levels up in the procedure's ancestor tree, the great-grandfather of the procedure.
Debuggers of Tru64 UNIX object files need to use the uplevel link information to determine which symbols are visible at a location in the program and to compute the addresses of local symbols in ancestor routines. When the debugger needs the current value or address of a name that might be defined as an uplevel reference, two separate actions may be required: finding the procedure that defines the currently visible instance of that name, and finding the address of the currently visible instance of that name. If only type information is required, finding the procedure that defines the name may be sufficient.
Finding the defining procedure is accomplished by repeatedly looking up the name in the local symbol table of a chain of procedures that extends from the current procedure through its chain of ancestors until either the name is found in a procedure or the end of the chain of ancestors is reached without finding the name. If this search terminates without finding the name, the debugger should conclude that the name is not visible by uplevel reference at the current location in the program.
When searching for the desired procedure, the debugger should count how many levels in the ancestor chain were traversed before finding the name. If zero levels were traversed, the name is defined within the current procedure and is not an uplevel reference. The number of levels traversed is assumed to be in the variable LevelsToGo in the algorithm below.
Finding the address for the name involves locating static link values and dereferencing them with appropriate offsets. Basically, while the number of levels to be traversed is greater than zero, find the static link symbol for the current level and obtain its value. Finally, add the desired symbol's offset from the real frame pointer to the final static link value.
The recommended algorithm for finding the address is as follows:
LevelsToGo = <from name lookup above>
NewProc = CurrentProcedure
NewFrame = FramePointerValue(CurrentProcedure)
Failed = false
while (LevelsToGo > 0 && !Failed)
StaticLink = FindStaticLinkSym(NewProc)
if (StaticLink == NULL)
Failed = true
else
NewFrame = *(NewFrame + StaticLink->symbol.offset)
Levels = StaticLinkLevels(StaticLink)
LevelsToGo = LevelsToGo - Levels
for (; Levels > 0; Levels--)
NewProc = NewProc->proc.parent
if Failed is true after executing this algorithm, required information about static links is missing in the symbol table, and an error has occurred. If LevelsToGo ends up less than zero, the optimizer's static link optimization has eliminated a static link level that would be needed to compute the address of the name. It is recommended that debuggers inform the user that optimization prevents the debugger from computing the address of the name.
If Failed is false and LevelsToGo is equal to zero, the address for the currently visible instance of the name is NewFrame plus the offset of the name with respect to the real frame pointer for NewProc.
The function StaticLinkLevels returns the integer at the end of the name for the indicated static link symbol.
This section explains how to interpret symbolic information for TLS symbols (identified by a storage class of scTlsdata or scTlsbss). See Section 3.3.9 or the Programmer's Guide for general information on TLS.
A TLS symbol's value contains its offset from the start of the TLS region for that object. This offset can be used at process execution time to determine the address of the TLS symbol for a particular thread.
A debugger can calculate TLS symbol addresses by looking up the address of the TLS region using run-time structures and adding the offset of the TLS symbol to that address. The following formula can be used to calculate TLS symbol addresses.
TLS sym address = *(TEB.TSD + __tlskey) + SYMR.value
A detailed description of this formula follows:
.lita or .got entry. This value should be accessed using the symbol __tlskey . In spite of the fact that __tlskey is a label symbol, no ampersand is used in this context because the value that the label points to is being retrieved. The address of __tlskey will need to be adjusted by the address mapping displacement in the same manner that the debugger adjusts addresses of text and data symbols..lita entry contains the constant offset (2048). This offset identifies the first and only TSD slot (256) that will be allocated for the TLS pointer. .got entry labeled by __tlskey is initially 0, indicating that the TSD slot has not been allocated yet. After the the object's initialization routines have run, a TSD key will be allocated and the .got entry will contain its offset.
Profile feedback data is stored in entries in the optimization symbols table with tag type PPODE_PROFILE_INFO. The data contained in this section is intended for Compaq internal use only. It contains execution profiling feedback used by compilers and the om utility.
Profile feedback data contains relative file descriptor and local symbol table indexes. If an object tool removes, adds, or rearranges relative file descriptors or local symbol table entries it must also remove all optimization symbol table entries including the profile feedback data.
From a user-program's point of view, an identifer's scope determines its visibility in different parts of the program. Programming languages provide facilities for declaring and defining names of procedures, variables and other program components inside various scoping levels. This section briefly discusses the concept of scope and then explains how it is represented in the symbol table. References are made to structures in the auxiliary symbol table; see Section 5.3.7.3 for details.
Generally speaking, the four main scoping levels in a program are block scope, procedure scope, file scope, and program scope. Most programming languages have constructs to implement at least these scoping levels. Figure 5-14 shows the hierarchy of these scopes.
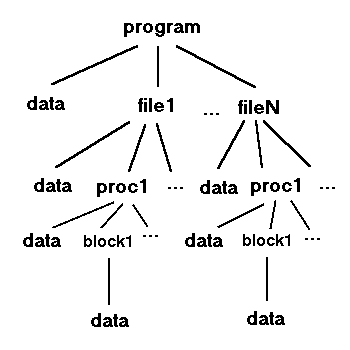
Names with block scope can only be referenced inside the declaring block. Blocks are delimited by begin and end markers, the syntax of which varies among languages.
Names with procedure scope are only recognized inside their enclosing subroutines. For instance, the names of formal parameters and local variables declared inside a procedure are accessible only to that procedure's executable statements.
Names with file scope can be referenced by any instruction within the file where they are declared. A file can be composed of procedures and data external to any procedure. Both external data names and procedure names can have file scope or program scope. Note that in a compilation involving only a single file or in a compilation for a programming language with no separate-compilation facilities, file scope and program scope are equivalent.
Names with program scope are visible everywhere in the program, even when the executable program is built from many source and header files. The linker must resolve these names or pass them to the dynamic loader to resolve. See Section 5.3.10 for more information about symbol resolution.
In the symbol table, procedure scope, file scope and program scope correspond to local, static, and global symbols, respectively. Block scope names are also local symbols. Local and static symbols appear in the local symbol table, and global symbols are in the external symbol table.
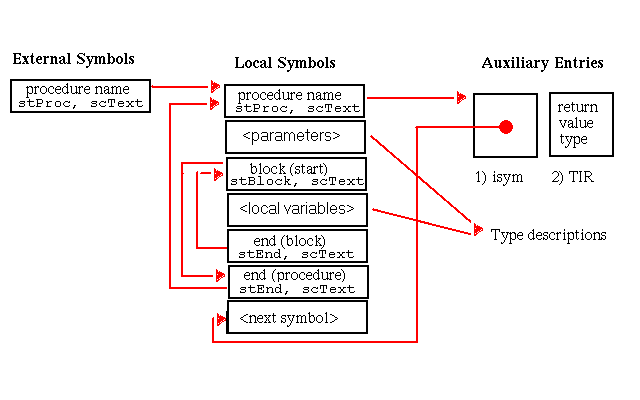
Although procedure symbols can only be global or static (with symbol types stProc and stStaticProc, respectively), procedure entries appear in the local symbol table to identify the containing scope of their local data. The set of symbols appearing in the local symbol table to describe a procedure scope and their associated auxiliary entries is shown in Figure 5-15. Global procedures also have entries in the external symbol table. As illustrated, the indices of these external entries point to the scoping entries in the local symbol table.
In this chapter, all diagrams of symbol table representations use arrows to show that one entry contains an index to another entry. For external and local symbol table entries, the index used is contained in theindexfield. For auxiliary symbols, theisymorRNDXRfield is the index used. Any exceptions to this general rule are noted in the diagrams.
A special instance of a procedure definition occurs for a procedure with no text. This type of procedure occurs only in the local symbol table and is very similar to the representation of other procedures. It is generally used for procedures that have been optimized away that still need to be represented for debugging or profiling information.
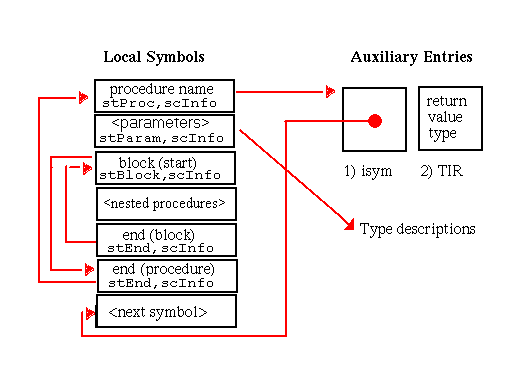
A procedure with no code can contain only nested procedures that also have no code associated with them. If a procedure with no code does not contain any nested procedures, the stBlock/stEnd symbol pair can be omitted from the representation.
The stProc symbol included in this representation is distinguished from similar stProc symbols by its value field that is set to addressNil (-1).
As in the case of procedures, file name entries appear in the local symbol table to define the file's scope. This representation is shown in Figure 5-17. Note that file symbols appear in the local symbol table only.
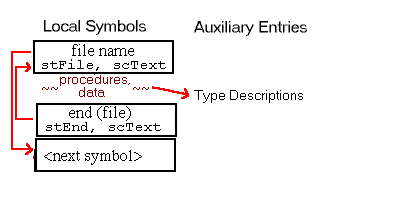
In general, the local symbol table denotes scoping levels with stBlock and stEnd pairs, as shown in Figure 5-18.
All symbols contained between these two entries belong to the scope they describe. Nested blocks are possible, and stEnd symbols match the most recent occurences of stBlock (or other opening symbol entries such as stProc or stTag).
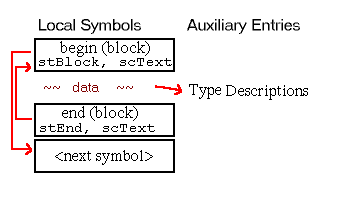
Block scopes occur in many languages. In C, they take the form of lexical blocks. In C++, declarations can occur anywhere in the code. In Pascal and Ada, nested procedures are possible, with local variables at any or all levels.
A C++ namespace is a mechanism that allows the partitioning of the program global name space. This partitioning is intended to reduce name clashing and provide greater program managability to C++ developers.
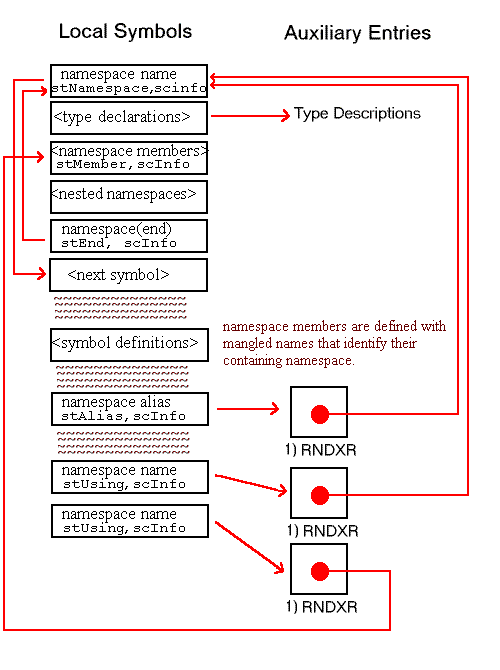
A namespace definition may exist only at the global scope or within another namespace. The namespace representation in Figure 5-19 shows a single contribution to a namespace. This representation may be replicated many times in the symbol table for a single namespace. A namespace definition may be continued within the same file or over multiple source files.
A single namespace contribution that spans multiple source files is represented as if it were contained entirely within the source file in which it began.
Namespaces may be aliased, allowing a single namespace to be refered to by multiple names. Namespace components may also be referenced without their namespace qualification if they are included within a scope by a using directive or using declaration. The representations of namespace aliases, using directives, and using declarations are shown in Figure 5-19. Namespace definitions, namespace component declarations, namespace aliases, using directives, and using declarations occur only in the local symbol table. Namespace component definitions may occur in the local or external symbol table.
The components of a namespace are represented in two parts: declarations and definitions. Namespace components that do not require definition must be declared in the namespace definition. Namespace components that are referenced by a using declaration must be declared in the namespace definition. All other namespace component declarations may be omitted from the namespace definition.
Namespace component names are mangled only as needed. Function and data definitions have mangled name definitions in the local or external symbol table. These entries are mangled for type-safe linkage and as a method of matching components with the namespaces to which they belong. Names of component declarations within a namespace definition may or may not be mangled. They are not required to include the namespace name in their mangled form.
Empty namespace contributions can be omitted, but at least one instance of a namespace definition must occur somewhere in the local symbol table. This definition is required because name mangling rules do not distinguish namespace component definitions from class member definitions.
Namespace aliases can occur in namespace, file, procedure or block scope in the local symbol table. The index value for the stAlias entry is an auxiliary table index. The auxiliary entry is a RNDXR record containing the local symbol table index of the stNamespace symbol in the first instance of a namespace definition within a compilation unit. For an alias of an alias, the RNDXR record can also contain the index of another stAlias symbol in the local symbol table. Section 9.2.5 provides an example of a namespace alias.
The stAlias symbol type may be used in future versions of the symbol table format as a general purpose symbol alias representation. The semantic interpretation of the stAlias symbol depends on the type of the symbol it aliases.
An unnamed namespace can be declared at the global scope or within another namespace. An unnamed namespace is unique within a compilation unit. Multiple contributions to a unique unnamed namespace are not allowed. Unnamed namespace contributions are included in the non-mergeable portion of a C++ header file.
Unnamed namespace components are subject to the same rules as named namespaces for declarations and definitions.
The stNamespace symbol for an unnamed namespace has no name, and its iss field is set to issNil. A compiler generated name is used to identify the unnamed namespace in the mangled names of unnamed namespace components. A convention for this special name is currently being investigated and will be identified in the next release of this document. The unnamed namespace example in Section 9.2.4 will use the name __unnamed until the actual naming convention has been determined.
A C++ using directive or a using declaration is represented by a symbol of type stUsing. It may occur in any scope in the local symbol table. The index value for the stUsing entry is an auxiliary table index. If the stUsing entry represents a using declaration for a single namespace component, the auxiliary entry is a RNDXR record containing the local symbol table index of a namespace component declaration. If the stUsing entry represents a using directive, its RNDXR auxiliary contains the local symbol table index of the stNamespace symbol in the first definition of that namespace in the compilation unit.
A using directive for a namespace alias is represented with a RNDXR auxiliary that directly references the aliased namespace. This representation contains no record of the alias referenced by the using directive.
Names are not required for stUsing entries, but they can be set to match the namespace or namespace component to which they refer.
Namespace components that are referenced by an stUsing symbol must be declared in the namespace definition.
Section 9.2.3 provides an example of namespace definitions and uses.
In C++, a special scoping mechanism is introduced to expand user-defined exception-handling capabilities. Exception handlers are defined to "catch" exceptions that are "thrown" by other functions. The symbol table must contain sufficient information to recognize the scope of a handler. The compiler generates special symbols to identify where exception handlers are valid.
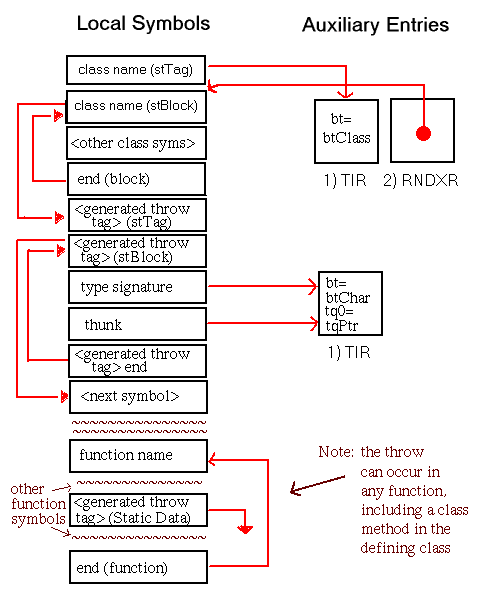
Fortran common blocks constitute another scoping level. Fortran uses common blocks as a way of specifying data that is global or shared between program units. A common block is global storage that can be named, allotted, accessed, and used by various subroutines. The block can be named or unnamed; unnamed blocks are known as "blank commons". Internal to the symbol table, blank commons are named "_BLNK_".
Figure 5-21 shows the symbolic representation of Fortran common blocks.
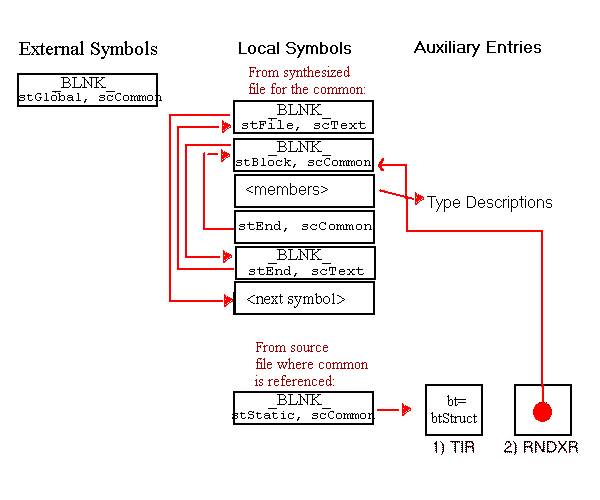
Because a Fortran common is represented as a synthesized file, it also has an entry in the file descriptor table. Furthermore, a global symbol with the same name is also present in the external symbol table.
An example of a Fortran common block can be found in Section 9.3.1.
Fortran also has a facility for creating alternate entry points in procedures. An alternate entry point is represented using an stProc, scText symbol. In the procedure descriptor table, an alternate entry point is identified by a lnHigh field with a value of -1. Procedure descriptors for alternate entry points follow the procedure descriptor for the primary entry point. In the local symbol table, an alternate entry point has an entry inside the scope of the procedure's main entry.
The representation of a procedure with an alternate entry point is shown in Figure 5-22
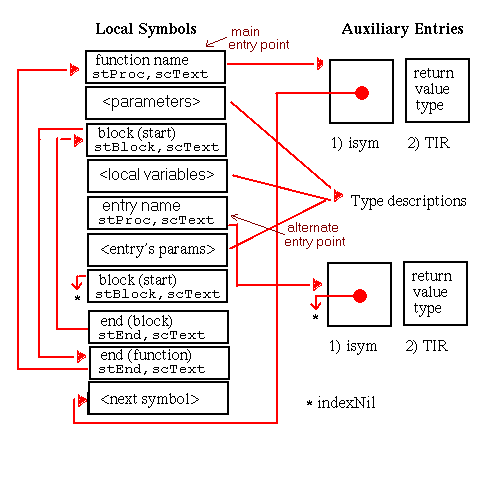
An example of Fortran alternate entries can be found in Section 9.3.2.
A data element's type dictates its size and interpretation in a programming environment. One of the symbol table's most important tasks is to represent data types in a compact and complete manner.
Type information is stored in the local and auxiliary symbol tables. This section provides guidelines for understanding the type information plus specific examples for depicting a range of types.
All programming languages have a set of simple types that are built into the language and from which other data types can be derived. Examples of simple types are integer, character, and floating point. Languages also provide constructs for creating user-defined types based on the simple types. For example, a C++ class can be built using any simple type or previously defined user-defined type and the language facility for declaring classes.
Similarly, a basic type in the symbol table is a building block from which each language constructs its type information. Basic type (bt) values directly represent many of the simple types for supported languages; for instance, the value btChar indicates a character. Other bt values represent language constructs for building aggregate types; a value of btStruct may be used, for example, to represent a C structure or Pascal record.
The symbol table uses approximately forty basic type values. The interpretation of some of these values is language dependent. See Table 5-4 for a list of all values.
Type qualifiers can be applied to basic types to create other data types. Examples are "pointer to" and "array of". Generally the number and order of type qualifiers is unrestricted.
The type qualifier "function returning" (tqProc) is not used in V3.13 of the symbol table. However, it is used in prior versions for variables declared as function pointers. This older representation uses a TIR record to store the function type in the bt value followed by as many type qualifiers as necessary. A major limitation of this representation is the inability to represent parameter types.
The symbol table currently uses eight type qualifiers. See Table 5-5 for a list of all possible values.
This section explains in detail the encoding of type descriptions in the symbol table. To fully describe the type of a symbol, the auxiliary symbol table must be created and referenced. Compilation with full symbolic information (-g option on system compilers) results in the creation of this table.
To correctly decode the type information, proceed sequentially, beginning with the symbol table entry. Several fields may be required from other symbol table structures:
st)
sc)
SYMR.index)
SYMR.value)
(FDR.lang)The first step is to determine whether the symbol contains an index of an auxiliary table description.
|
Symbol Type |
Storage Class |
Conditions |
|
|
|
Any |
None |
|
|
|
Any |
None |
|
|
|
Any |
None |
|
|
|
Any |
Local symbol table |
|
|
|
Any |
Local symbol table only |
|
|
|
|
Inside an |
|
|
|
|
None |
|
|
|
|
None |
|
|
|
Any |
Local symbol table only |
|
|
|
Any |
None |
|
|
|
|
None |
|
|
|
|
None |
|
|
|
|
None |
|
|
|
|
None |
|
|
|
|
None |
|
|
|
|
None |
|
|
|
|
None |
|
If the index does represent a record in the auxiliary symbol table, the interpretation of the first auxiliary entry (AUXU) depends on the type of the symbol:
stProc or stStaticProc and the symbol is a local symbol, the indexed AUXU is an isym and the second AUXU is a TIR. External procedure symbols do not have descriptions in the auxiliary table.
stInter, stAlias, or stUsing, the indexed AUXU is an RNDXR and the type description does not contain a TIR.
stBlock symbol inside an scVariant block, the symbol entry's value field is an index into the auxiliary table. This special case is the only one where the value is used as an auxiliary symbol pointer. In all other cases, it is the index field that potentially indexes the auxiliary table type description.
AUXU is a TIR. The next task is to examine the contents of the TIR. The TIR contains constants representing the basic type of the symbol and up to six type qualifiers, labeled tq0-tq5. If a type has more than one qualifier, they are ordered from lowest to highest. Lower qualifiers are applied to the basic type before higher qualifiers. All unused tq fields are set to tqNil, and no tqNil fields are present before or between other type qualifiers.
In addition to the basic type and type qualifiers, the TIR contains two flags: an fBitfield flag to mark whether the size of the type is explicitly recorded, and a continued flag to indicate that the type description is continued in another TIR. If fBitfield is set, the TIR is immediately followed by a width entry. If more than six type qualifiers are required for the current definition, the description is continued, and the continued flag is set. If exactly six type qualifiers are needed, all six fields are used and the continued flag is cleared.
To illustrate, consider the type "array of pointers to integers". The basic type is "integer" and has two qualifiers, "array of" and "pointer to". Each element of the array is a "pointer to integer". Therefore, the qualifier "pointer to" must be applied first to the basic type "integer". In this example, the qualifier "pointer to" is lower than the qualifier "array of". The contents of the TIR are as follows:
bt: btInt
tq0: tqPtr
tq1: tqArray
tq2: tqNil
tq3: tqNil
tq4: tqNil
tq5: tqNil
continued: 0
fBitfield: 0
The contents of the TIR dictate how to interpret any subsequent records. The records appear in a prescribed order:
fBitfield flag is set, a width record follows the TIR.
btPicture, the next four records contain integer values: the string table index of the picture string, the length, precision and scale.
btScaledBin, the next three records contain integer values: a basic type, the precision and scale.
btStruct, btUnion, btEnum, btClass, btIndirect, btSet, btTypedef, btRange, btRange_64, btDecimal, btFixedBin, or btProc, the next record is an RNDXR.
rfd field of the RNDXR contains the value ST_RFDESCAPE, the next record is an isym.
btRange, the next two records are dnLow and dnHigh.
btRange_64, the next two records are dnLow records and the two after that are dnHigh records.
btDecimal or btFixedBin, the next two records contain integer values: the precision and scale.
TIR, the following symbols occur:
RNDXR, again possibly followed by an isym
dnLow records (depending on whether the array is tqArray or tqArray_64)
dnHigh records (depending on whether the array is tqArray or tqArray_64)
width records (depending on whether the array is tqArray or tqArray_64)
continued flag is set, the next record is another TIRFor a type description containing more than one TIR, the fields of all TIR records are interpreted in the same way. When a TIR is reached with the flag cleared and any records associated with that TIR have been decoded, the type description is complete.
As an example, consider an array of structures with the fBitfield flag set. A total of seven auxiliary records can be used to describe the type:
TIR with a basic type of btStruct and with tq0 set to tqArray
width record. The size of the basic type
RNDXR record. A pointer to the structure definition in the local symbol table
RNDXR record. A pointer to the array index type description elsewhere in the auxiliary table
dnlow record. The lower bound of the array's range
dnhigh record. The upper bound of the array's range
width record. The distance in bits between each element in the arrayIf the continued flag of the TIR is cleared, the width record corresponding to the array qualifier is the final AUXU for this type description.
For another view of this process, see Figure 5-23. Each box represents one auxiliary entry belonging to the symbol's type description. Using the flowchart, an ordered list of entries can be assembled.
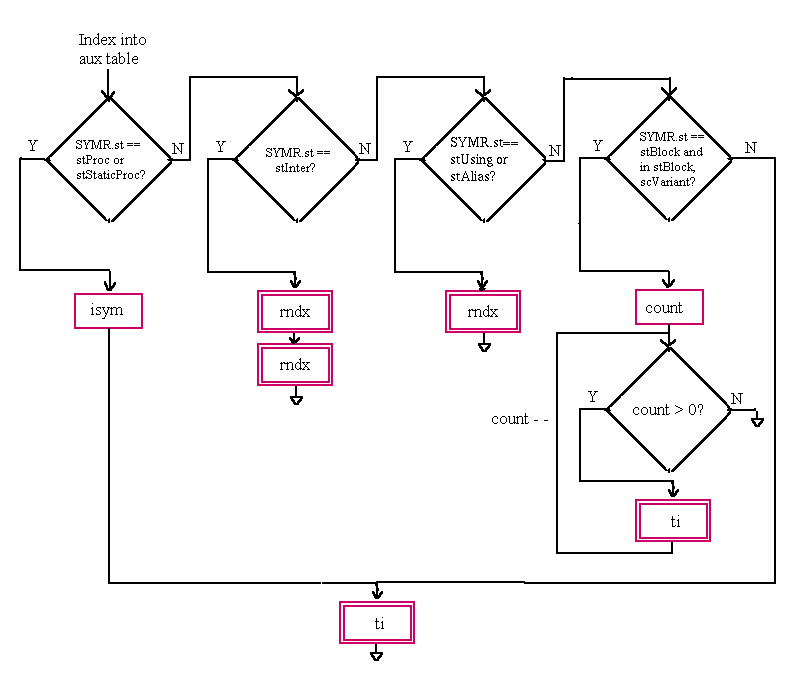
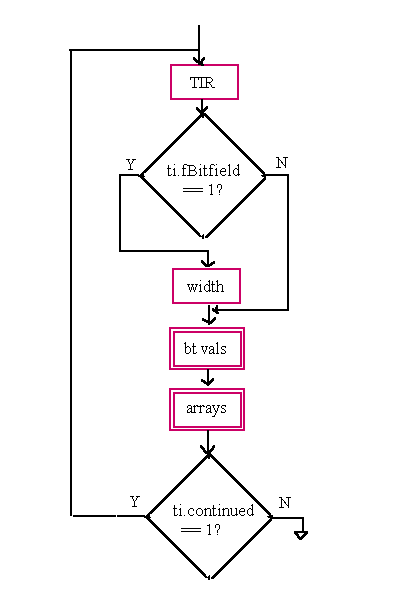
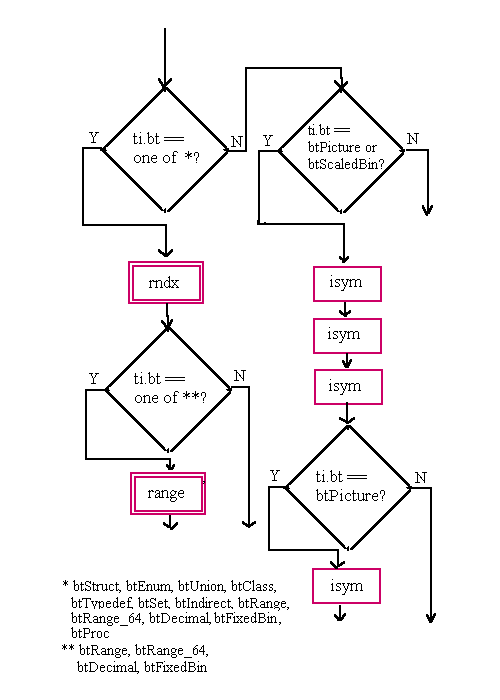
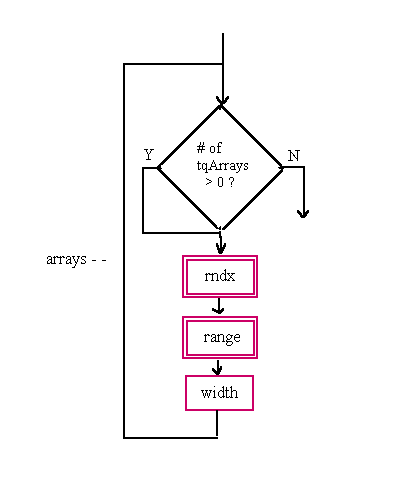
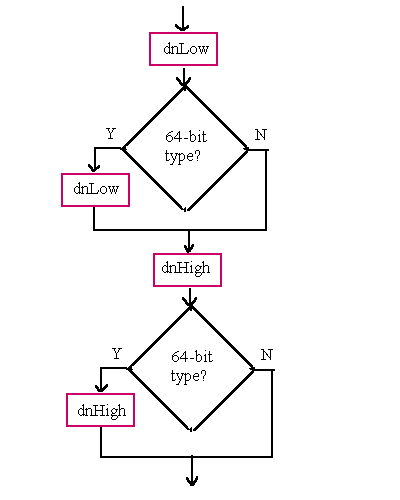
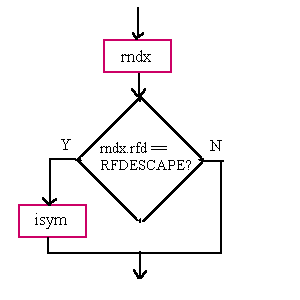
The final step is to decode the RNDXR records. The basic types that are followed by RNDXR records require reference to another local or auxiliary symbol to complete the type description. Interpret the RNDXR records as follows:
btStruct,btUnion, btEnum, btClass, btProc, or btTypedef, the index field of the RNDXR points into the local symbol table. The specified local symbol is the start of the definition of the structure, union, enumeration, class, or user-defined type. For btProc, the referenced local symbol is the start of the set of symbols defining the procedure's signature.
btSet, the RNDXR points into the auxiliary symbol table. The specified record is the start of the description of the type of each element in the set.
btIndirect, the RNDXR points into the auxiliary symbol table. The specified auxiliary record is the start of the description of the referenced type.
btRange, the RNDXR points into the auxiliary symbol table. The specified auxiliary record is the start of the description of the type being subranged.
btFixedBin, the rfd field of the RNDXR contains a Boolean value. If rfd is true, the base is decimal; if rfd is false, the base is binary. The index field represents a type code.
btDecimal, the rfd field of the RNDXR contains the value 1 for 4-bit digits (packed decimal) or 2 for 8-bit digits (zoned decimal). The index field represents a type code.Additionally, the index of every RNDXR used as a pointer must be mapped through the relative file descriptor table (see Section 5.3.2.1), if the table exists. The rfd field of the record controls this mapping. The following algorithm can be used to locate the symbol referenced by the relative index record:
if (RNDXR.rfd == ST_RFDESCAPE)
RFD = (++AUXU).isym
else
RFD = RNDXR.rfd
if (HDRR.crfd) /* RFD table exists */
IFD = (current FDR's RFD table)[RFD]
else
IFD = RFD
if (SYMR needed)
SYMBASE = FDR[IFD].isymBase
SYMR = SYMBASE[RNDXR.index]
else if (AUXU needed)
AUXBASE = FDR[IFD].iauxBase
AUXU = AUXBASE[RNDXR.index]
This section provides sketches of type representations in the local and auxiliary symbol tables. The connections between the two tables is depicted for each type. This form of representation is only possible when full symbolic information is present.
Note that external symbols as well as local symbols reference the auxiliary table, although the examples in this chapter use local symbols only.
A pointer is a variable containing the address of another variable. A pointer is represented by a tqPtr type qualifier modifying another type. A pointer is represented by a single symbol with an entry in the auxiliary table, as shown in Figure 5-29.
Note that if the pointer referenced a user-defined type, such as a class or structure, the TIR would be followed by an RNDXR (and possibly an isym).
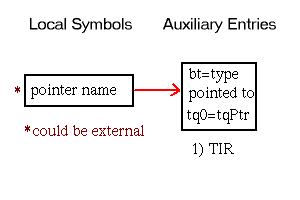
The combination of type qualifiers tqFar and tqPtr are used to represent a short (32-bit) pointer. This pointer type is used with the XTASO emulation.
An array is a list of elements that all have the same type. Arrays may be fixed size and allocated at compile time or dynamically sized and allocated at run time. This section describes the fixed-size array symbol table representation. For information on Fortran dynamic arrays, see Section 5.3.8.9. For conformant arrays in Pascal and Ada, see Section 5.3.8.10.
An array is represented by a tqArray or tqArray_64 type qualifier applied to another type. This second type describes the type of all elements in the array. In the local or external symbol table, a single entry represents an array. Figure 5-30 shows the symbol table description for an array.
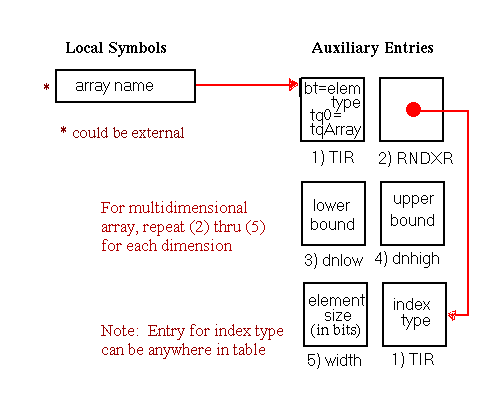
Note that for an array of elements of a user-defined type, such as a class or structure, another RNDXR (and possibly an isym) would be inserted between the TIR and the RNDXR describing the subscript type.
If an array has multiple dimensions, the symbols describing the dimension appear in the order of innermost to outermost. For example, the following declaration produces a TIR with the tqArray qualifier followed by the RNDXR and range description for 0-1 followed by the entries for the dimension 0-99:
float floattable[100][2]
Some arrays may have dimensions too large to represent in the 32-bit format shown in Figure 5-30. Such arrays are represented using a 64-bit format in which two auxiliary entries are used for the dimension bounds and size. Figure 5-31 illustrates the 64-bit representation.
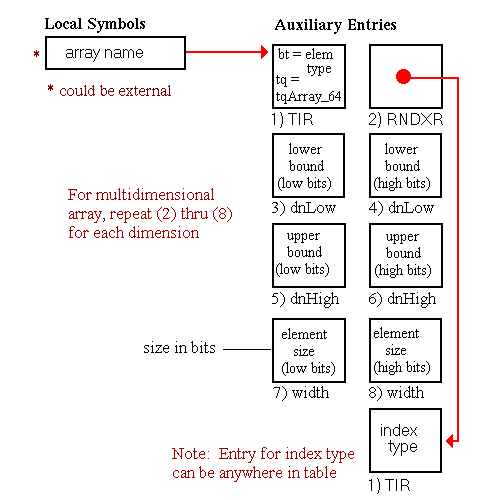
This section applies to data structures in languages other than C++. For the C++ structure, union, or enumerated type representation, see Section 5.3.8.6.
Structures, unions, and enumerated types have a common representation. All three are identified using "tags" and contain zero or more fields. In the symbol table, the tag is the name associated with the starting stBlock symbol for the structure's set of local symbols. Note that it may be empty because the tag is optional. Symbols for fields follow. The definition is completed by a block-end symbol matching the block-start symbol.
Figure 5-32 contains a graphical depiction of this set of symbols.
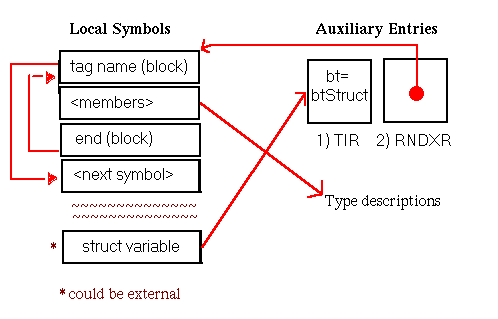
The structure members have auxiliary table indices pointing to their type descriptions.
Untagged structures and unions are represented with a NULL tag name. Unnamed structures can be embedded in other structures and are represented as a NULL-named member of the outer structure. See Section 9.1.1 for an example of an unnamed structure.
A structure can contain a field that is a pointer to itself. This field is represented by an stMember symbol with an auxiliary table entry that references the beginning of the structure's block of local symbols, as shown in Figure 5-33.
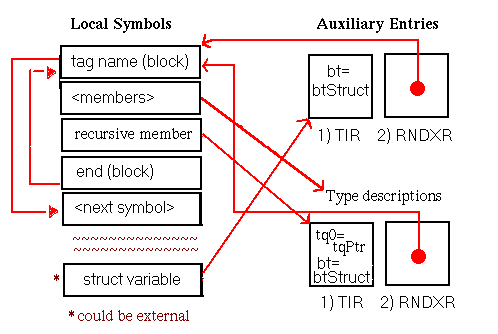
When a field within a structure is itself a structure, the compiler may choose to generate the structure definitions either sequentially or embedded, as shown in Figure 5-34.
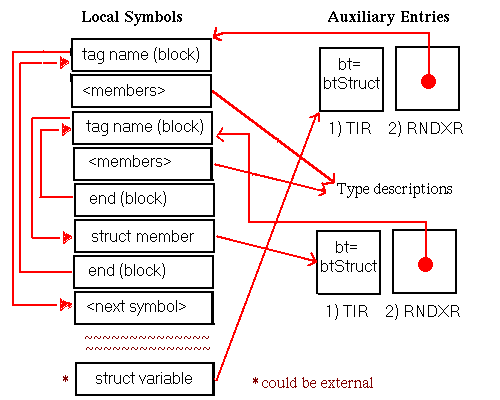
The following declaration might result in the nested structure representation:
struct line {
struct point {
float x, y;
} p1, p2;
};
Most languages allow programmers to choose alternate names, or aliases, for data types. The alias created by such a facility (such as C's typedef) is represented as a single local symbol entry that has a pointer to its type description in the auxiliary table. The auxiliary entry contains a pointer to the definition of the type name, as shown in Figure 5-35.
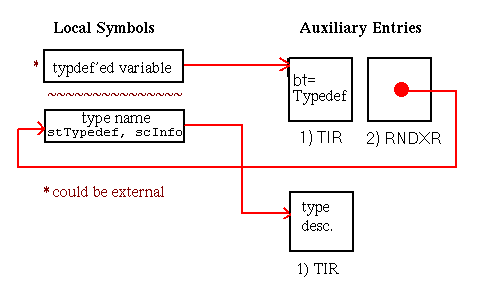
Languages such as C and C++, which allow pointers to functions, represent the type of the function pointer using a special stProc/scInfo block describing the parameters and return value for the function as shown in Figure 5-36.
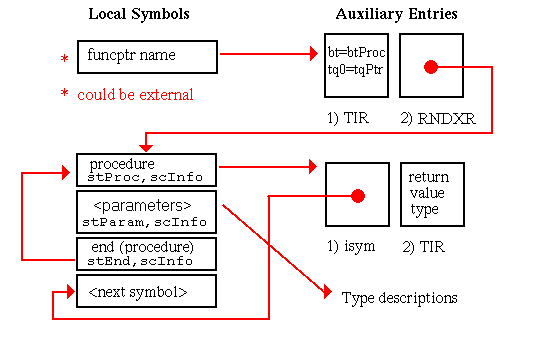
The stProc/scInfo entry has its value set to -2, which distinguishes it from similar entries used to represent procedures with no text and C++ member functions. The stProc/scInfo and stEnd/scInfo entries have null names in the function pointer representation. The parameters are optional and may or may not be named.
This representation for function pointers is new in V3.13. The previous representation used the combination of type qualifiers tqPtr and tqProc in the TIR of the function pointer variable. Prior to V3.13, it was not possible to represent the parameter types for a function pointer.
A C++ class resembles an extended C structure. One major distinction is that class fields (referred to as "members") can be functions as well as variables. The set of symbols created for a class is organized as follows:
Another characteristic of classes is that symbols are defined implicitly. For example, all classes have an operator= operator-overloading function included in the class definition and a "this" pointer to its own type as a parameter to all member functions. These symbols are always included explicitly in the symbol table description.
Figure 5-37 is a graphical representation of the set of symbols for a class.
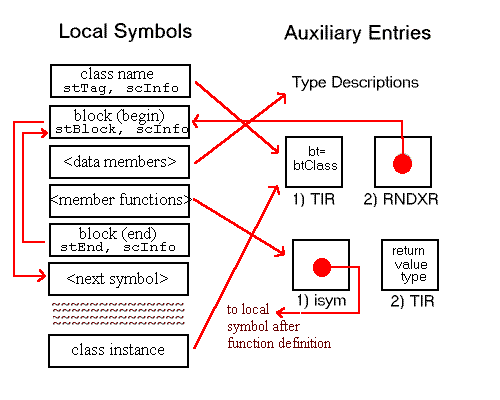
Class members, including member functions, have auxiliary references that point to their type descriptions. Note that member functions are represented as prototypes. The set of symbols defining the member function is elsewhere in the symbol table. To locate the definition of a member function, a name lookup can be performed using the mangled name of the member function with its class name qualifier. See Section 5.3.10.3 for information on name mangling.
C++ structures, unions, and enumerated types are represented the same way as classes. The different data structures are distinguished by basic type value.
The symbol table does not represent class member access attributes.
Examples of base and derived classes can be found in Section 9.2.1.
The representation of empty classes or structures in C++ is shown in Figure 5-38.
Hierarchical groups of classes can be designed in C++. A base class serves as a wider classification for its derived classes, and a derived class has all of the members and methods of the base class, plus additional members of its own. In the symbol table, the set of symbols denoting a derived class is nearly identical to that for a non-derived class. The derived class includes an additional stBase or stVirtBase symbol that identifies its corresponding base class, and it does not need to duplicate the definitions for the base class members. This representation is shown in Figure 5-39.
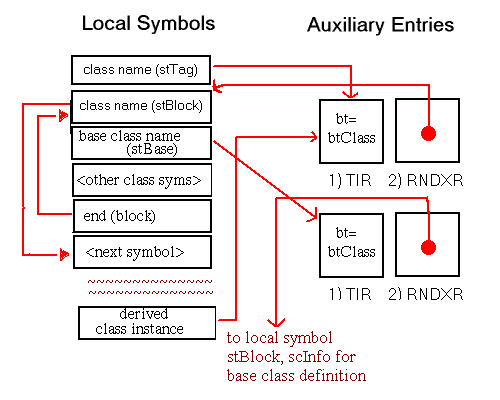
The representation of virtual base classes for C++ relies on the definition of a special symbol that identifies the virtual base table. The name for this symbol is derived from the name of the class to which it belongs. For example, the virtual base table symbol for class C5 would be named "_btbl_2C5". This table contains entries for base class run-time descriptions.
A class can include the special member "_bptr". This class member is a pointer to the virtual base table for that class.
The value field for a virtual base class symbol (stVirtBase/scInfo) serves as an index (starting at 1) into the virtual base class table.
Templates are a C++-specific language construct allowing the parameterization of types. C++ class templates are represented in the symbol table for each instantiation, but not for the template itself. The set of class symbols is unchanged from the set shown in Figure 5-37.
Interludes are compiler generated functions in C++. They are represented in the local symbol table with special names starting with the "__INTER__" prefix. Their representation in the symbol table makes use of two RNDXR aux entries to identify the related member function and the actual interlude function, both of which are local symbol table entries.
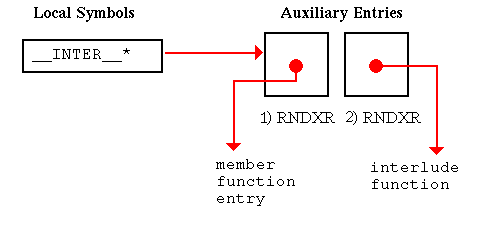
A Fortran90 array descriptor is a structure that describes an array: its location, dimensions, bounds, sizes, and other attributes. Array descriptors are described in detail in the Fortran 90 User Manual for Tru64 UNIX. Fortran90 includes several types of arrays for which the dimensions or dimension bounds are determined at run time: allocatable arrays, assumed shape arrays, and array pointers.
Two symbol table representations can be used for an array descriptor. The default representation describes the array descriptor itself. The alternate representation describes what is known of the array itself at compile time.
No matter what symbolic representation is used, symbols of this type point to a data location at which the array descriptor is allocated. One of the array descriptor fields contains a pointer to the actual array. Other fields are used to describe the attributes of the array. Fields that describe the number of dimensions and upper and lower bounds are filled in at run time.
By default, array descriptors are described by a structure tag representation. Most of the array descriptor fields are represented as structure members. (Excluded fields are not needed by debuggers.) Special tag names are used to identify array descriptor structure definitions: $f90$f90_array_desc (assumed-shape array), $f90$f90_ptr_desc (pointer to array) and $f90$f90_alloc_desc (allocatable array). Figure 5-41 shows the format of this representation.
Some compilers may emit other fields in addition to those shown in Figure 5-41. A consumer's ability to interpret additional fields depends on its knowledge of the producing compiler.
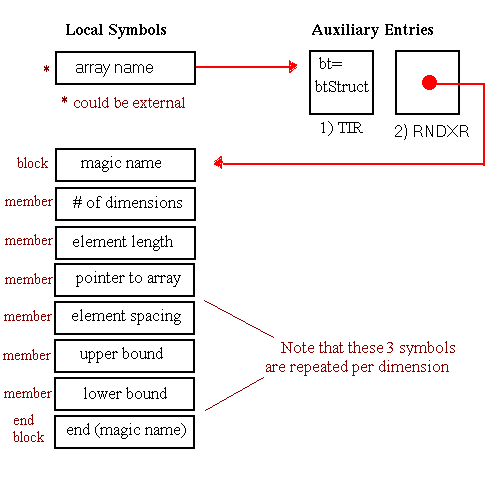
An example of the default Fortran array descriptor representation can be found in Section 9.3.3.
An alternate representation for array descriptors may be found in symbol tables prior to V3.13. The overloaded basic type value 28 indicates an array descriptor in the TIR, and dimension bounds are set to [1:1] indicating their true size is unknown. The alternate representation does not provide any information describing the contents of the array descriptor itself, so debuggers must assume a static representation for the descriptor and lookup the fields at their expected offsets.
This representation is substantially more compact in the local symbol table, but it provides no way to distinguish between the different types of array descriptors.
Figure 5-42 shows the format of the older array descriptor representation.
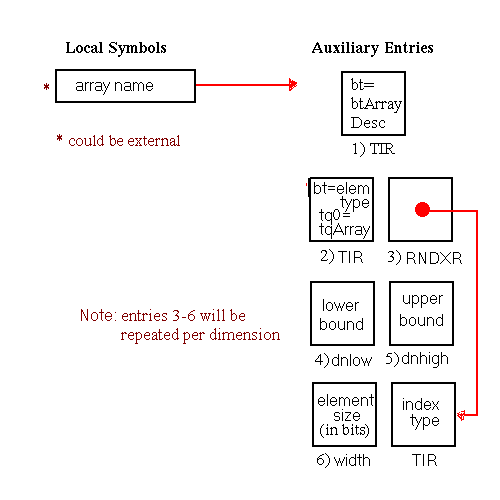
Full details are not currently available for Pascal's conformant array representation. A Pascal conformant array is very similar to Fortran's assumed shape arrays. It is an array parameter with upper and lower dimension bounds that are determined by the input argument. A conformant array is represented by an array descriptor. The special names used and the format of the array descriptor differ from those used for Fortran. The DEC Pascal release notes contain additional information on conformant arrays.
A variant record is an extension to the record data type, which is a Pascal or Ada data structure akin to a C struct and is represented in the same manner in the symbol table. The variant part of the record consists of sets of one or more fields associated with a range of values. Only one such set is part of the record, and it is selected based on the value of another record field. Any number of variant parts can be embedded in a single record.
The local symbol table entries for the variant part of a record are contained within a block with the storage class (sc value) scVariant. The value field of the stBlock entry contains the index of the local symbol entry for the member of the record whose value determines which variant arm is used. The variant block contains multiple inner blocks, each representing a variant arm. The value field of each of these block entries is an auxiliary table index. Each auxliary table entry starts with a count, which indicates how many range entries follow. The range entries describe the values associated with the block.
Figure 5-43 is a graphical representation of a variant record.
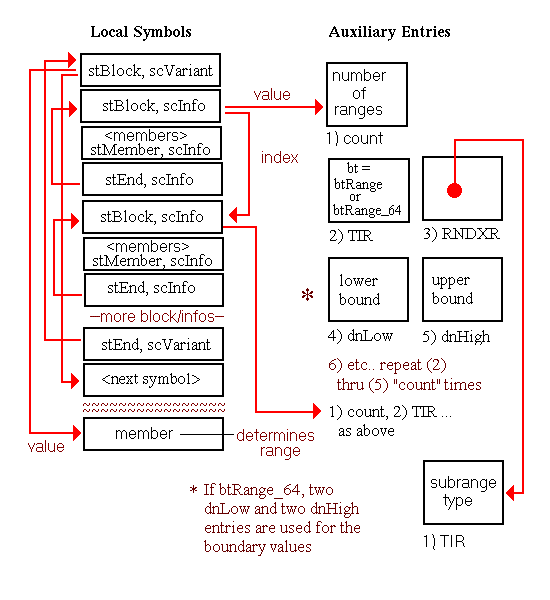
Prior to V3.13 of the symbol table, variant records were represented differently. Figure 5-44 depicts the older representation.
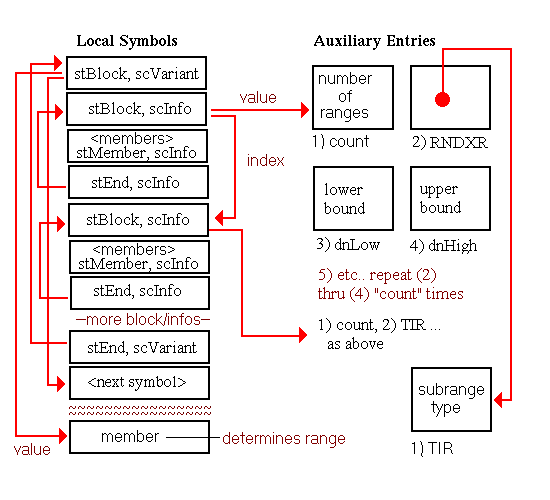
An example of a Pascal variant record can be found in Section 9.4.3.
A subrange data type defines a subset of the values associated with a particular ordinal type (the "base type" of the subrange). Ordinal types in Pascal include integers, characters, and enumerated types. The symbol table representation of a subrange uses the btRange or btRange_64 type followed by an auxiliary index identifying the base type and entries providing the bounds of the subrange. The 32-bit representation is shown in Figure 5-45 and the 64-bit representation is shown in Figure 5-46.
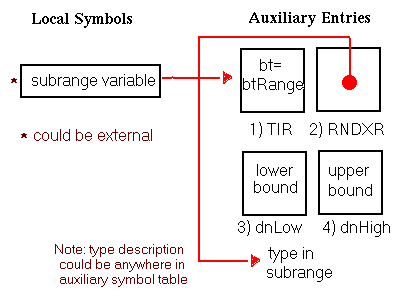
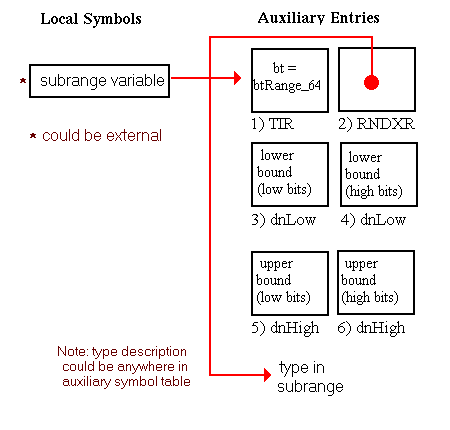
An example of a Pascal subrange can be found in Section 9.4.2.
A set is a data type that groups ordinal elements in an unordered list. The arithmetic and logical operators are overloaded in Pascal; this enables them to be used with set variables to perform classic set operations such as union and intersection. A special auxiliary type definition btSet exists to identify this type. The symbol table representation is depicted in Figure 5-47.
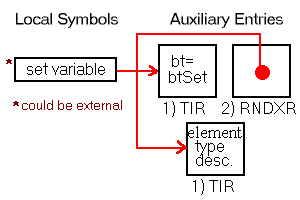
The element type for a set is typically a range or an enumeration. An example of a Pascal set can be found in Section 9.4.1.
A variety of special symbols are used throughout the symbol table to convey call frame information, special type semantics, or other language specific information. These names are reserved for use by compilers and other tools that produce Tru64 UNIX object files.
|
Name |
Purpose |
|
|
Uplevel link. See Section 5.3.4.4. |
|
|
Fortran unnamed common block. See Section 5.3.6.6. |
|
|
Fortran alias for main program unit. See Section 5.3.10.4. |
|
|
Generated parameter for Fortran routines. It contains the length of <ARGNAME>, a parameter of character type. |
.lb_<ARRAY>.<dim> .ub_<ARRAY>.<dim> |
Lower and upper bounds of particular dimensions of arrays�when the array has an explicit shape, yet some bounds come from non-constant specification expressions (array arguments in Pascal and Fortran routines). |
$f90$f90_array_desc $f90$f90_alloc_desc $f90$f90_ptr_desc |
Variants of Fortran-90 described arrays (assumed shape, ALLOCATABLE, and POINTER, respectively). See Section 5.3.8.9. |
|
|
Fortran-generated typedef describing the type of a variable pointed to by a CRAY pointer. |
|
|
Fortran generated typedef describing the type of a scalar with the POINTER attribute. |
|
|
DECC++ compiler-inserted name for unamed classes and enumerations. |
|
|
Hidden parameter in C++ member functions that is a pointer to the current instance of the class. See Section 5.3.8.6. |
|
|
Hidden C++ class member containing the virtual function table. See example in Section 9.2.2. |
|
|
Hidden C++ class member containing the virtual base class table. See example in Section 9.2.2. |
|
|
Global symbols for C++ virtual function tables. See example in Section 9.2.2. |
|
|
Global symbols for C++ virtual base class tables. See example in Section 9.2.2. |
|
|
Hidden argument to C++ constructors controlling descent (in the face of virtual base classes). |
|
|
Structure used to maintain a list of C++ global deconstructors. |
|
|
C++ static procedure used for global constructors. |
|
|
C++ static procedure used for global destructors. |
|
|
C++ static procedure used to provide a defaulted argument value. |
|
|
C++ interlude. See example in Section 9.2.2. |
|
|
C++ unnamed namespace components. See example in Section 9.2.4. |
Among the linker's chief tasks is symbol resolution. Because most compilations involve multiple source files and virtually all programs rely on system libraries, a process is necessary to resolve conflicting uses of global symbol names. The linker must decide which symbol is referenced by a given name. This section highlights the major issues involved in that decision. Related information is contained in Section 6.3.4 and the Programmer's Guide.
Symbol table entries provide information relevant to performing symbol resolution. External symbols with a storage class of sc(S)Undefined, sc(S)Common, or scTlsCommon must be resolved before they are referenced. By default, the linker will not mark an object file with unresolved symbols as executable. However, linker options give programmers a fair measure of control over its symbol resolution behavior. See ld(1) for more information.
Symbols referenced, but not defined in the main executable of an application must be matched with definitions in linked-in libraries. The linker combines objects, archives, and shared libraries while attempting to resolve all references to undefined symbols. The Programmer's Guide covers related topics in detail, such as how to specify libraries during compilation and the search order of libraries.
In general, main executable objects and shared libraries are searched before archive libraries. If no undefined external symbols remain, archive libraries in the library list do not have to be searched, because archive members are only loaded to resolve external references. Archives are not used to find "better" common definitions (see Section 5.3.10.2), and no archive definitions preempt symbol definitions from the main object or shared libraries.
Symbols with common storage class are a special category of global symbols that have a size but no allocated storage. Symbols with common storage class should not be confused with Fortran common symbols, which are not represented by a single symbol table entry. (See Section 5.3.6.6 for a description of Fortran common symbols.). Common storage classes are scCommon, scSCommon, and scTlsCommon.
The symbol definition model used by Tru64 UNIX allows an unlimited number of common storage class symbols with the same name. Ultimately, the "best" of these must be selected (by the linker or the loader) during symbol resolution. The criteria used to select the best symbol definition include the symbol's allocation status and size.
The symbol table does not provide an "allocated common" storage class. Common storage class symbols adopt a new storage class when they are allocated. Typically, their new storage class is scBss or scSBss or scTlsBss. On the other hand, the dynamic symbol table does explicitly distinguish common storage class symbols that have been allocated. See Section 6.3.4 for more information on dynamic symbol resolution.
A symbol reference is resolved according to the following precedence rules:
Precedence is given to symbol definitions with storage allocation to minimize load time common allocation and redundant storage allocations in shared objects. The loader is capable of allocating space for common storage class symbols, but this should only be necessary when a program references an allocated common symbol in a shared library that is later removed from that shared library.
Note that Fortran common block representations use common storage class symbols Another very frequent occurrence of a common storage class symbol is a C-language global variable that does not have an initializer in its declaration.
Another issue related to symbol resolution is the need to "mangle" user-level identifiers. For example, C++ allows function overloading, prototyping, and the use of templates�all of which can result in the occurrence of the same names for different entities. The solution employed by the symbol table is to use mangled names that derive from the symbol's type signature.
Object file consumers, such as debuggers and object dumpers, need to "demangle" the identifiers so they can be output in a form that is recognizable to the user. For linking and loading, the mangled names are used for symbol resolution.
The encoding of C++ names is described in the manual Using DEC C++ for Tru64 UNIX Systems.
Other compilers may write symbol names that are modified by prepending or appending special characters such as dollar sign ($) or underscore (_) or by prepending qualifier strings such as file names or namespace names. Uppercasing of names is also common for certain languages such as Fortran. All of these transformations fall into the general category of mangled names. Refer to the release notes for specific compilers for additional information.
Compilation of a program involving multiple source languages introduces additional symbol resolution issues. One important task is resolving the main program entry point because conflicting "main" symbols may be present in the different files. For C and C++, the symbol "main" is the main program entry point, but for other languages, "main" will either be an alias for the main program or an interlude. DEC Fortran and DEC COBOL provide interludes that perform some language specific initializations and then call the real main program entry point. For DEC FORTRAN the main program is "MAIN__" and for DEC COBOL the main program is "__cobol_main". DEC PASCAL provides a "main" symbol that aliases the actual main program symbol.
The symbols "MAIN__" and "__cobol_main" can both be present in a mixed language program, and either, neither, or both can be used by the program. Debuggers can set a breakpoint in the user's main program by applying some precedence for selecting the most appropriate symbol. For a mixed language program, there is a slight chance that "MAIN__" or "__cobol_main" will be present but never called.
TLS symbols, like non-TLS symbols, can be undefined or common. Unresolved TLS symbols are identified by the storage class scTlsUndefined, and TLS commons have the storage class scTlsCommon. The symbol resolution process for TLS names is similar, but separate; TLS symbols cannot be resolved to non-TLS symbols or vice versa.
TLS common symbols are resolved in the same manner as other common storage class symbols (see Section 5.3.10.2), except that, again, only TLS symbols are candidates for resolution.
Another rule special to TLS is that symbol definitions for TLS common and undefined symbols cannot be imported from shared libraries.
Language-specific characteristics are pervasive in the symbol table, particularly in the local, external, and auxiliary symbol tables. See Section 5.2 and Section 5.3.7 for information on language-specific values.
The lang field of the file descriptor entry encodes the source language of the file. This field should be accessed prior to decoding symbolic information, especially type descriptions. This section highlights, by language, language-specific features represented in the symbol table. Additional information on certain features is available elsewhere in this chapter.
In Fortran, it is possible to create multiple entry points in subroutines. A subroutine has one main entry point and zero or more alternate entry points, indicated by ENTRY statements. See Section 5.3.6.7 for their representation in the symbol table.
Fortran90 array descriptors include allocatable arrays, assumed-shape arrays, and pointers to arrays. Their representation in the symbol table is discussed in Section 5.3.8.9.
Modules provide another scoping level in Fortran90 programs. The symbol table representation for modules has not yet been implemented.
C++ classes encapsulate functions and data inside a single structure. Classes are represented in the symbol table using a btClass basic type and the stBlock/stEnd scoping mechanism. See Section 5.3.8.6.
Templates provide for parameterized types. At present, no special symbol table values are related to templates. The template itself is not represented; rather, entries that correspond to each instantiation are generated. Template instantiations are distinguished by mangled names based on their type signatures.
C++ namespaces, like Fortran modules, offer an additional scope for program identifiers. Again, they are not yet implemented in the symbol table.
The C++ concepts of private, protected, and public data attributes are not currently represented in the symbol table. The C++ concept of "friend" classes and functions are also not represented.
Pascal conformant arrays are function parameters with array dimensions that are determined by the arguments passed to the function at run time. See Section 5.3.8.10.
Variant records are an extension of the record data structure. Variant records allow different sets of fields depending on the value of a particular record member. See Section 5.3.8.11.
Nested procedures are supported in these languages. They are represented using standard scoping mechanisms discussed in Section 5.3.6 and uplevel references described in Section 5.3.4.4.
Sets and subranges are user-defined subsets of ordinal types. Sets are unordered groups of elements, which can be manipulated with the classic set operations. Subranges are ordered and are used with the usual operators. See Section 5.3.8.12 and Section 5.3.8.13.
Ada subtypes of ordinal types are represented in the same manner as Pascal subranges.